O que é UI Design
O que é UI Design
O User Interface Design (Design de Interface do Usuário), é aonde ocorre a interação e controle de um dispositivo, software, aplicativos ou sites por parte do usuário. Esta interação pode ocorrer através de botões, menus e demais componentes da interface.
Projetos de UI podem ser utilizados para garantir as necessidades que o usuário irá utilizar, e assim criando uma interface que contenha elementos de fácil utilização e acesso, para que seja alcançado um bom nível de experiencia amigável ao usuário e não cause frustações ao utilizar um sistema.
Atualmente é muito importante entender que User Interface não é apenas como uma aplicação se parece e quais cores foram utilizadas para tal processo, também se baseia como uma aplicação irá funcionar e como a interação do usuário será realizada indo além da aparência. Para que possa ser alcançado devemos utilizar a User Experience (UX Design) que por mais que os nomes sejam parecidos são abordagens bem diferentes, já que UX estará relacionado com a experiencias e os sentimentos do usuário e a UI será a maneira com que este usuário alcançara a experiencia.
Diferença entre UI Design e UX Design
UI é quando falamos de criação de interfaces para que o usuário final possa interagir com a aplicação, utilizando as melhores práticas para que seja criado uma interface de fácil utilização e visualização de todas informações.
UX normalmente confundido com UI por serem apresentados juntamente na interface, mas a verdade, é que UX se encaixa na sensação que um usuário irá ter ao navegar por uma interface. Assim a UX é responsável por criar um sentimento bom ao usuário enquanto os mesmos utilizam a aplicação tornando esta experiencia em algo inesquecível. UX também está relacionada com a forma que as funções principais serão utilizadas pelo usuário, usabilidade criação de novos cadastros, e pesquisas.

Preocupações com a Usabilidade
É necessário que um usuário consiga identificar elementos de interface e o que os mesmos realizam de uma forma clara. Por isso a criatividade ao compor um elemento é muito importante, mas deve se levar em conta os padrões que os usuários já estão acostumados a utilizar e reconhecer facilmente.
Um exemplo fácil de utilizar e a cor de botões que estamos acostumados a utilizar e ver aplicações. Aonde a maioria utiliza a cor verde para ações positivas como salvar, adicionar, e a cor vermelha para ações de negação com deletar. Se trocar as cores para as ações podem acontecer confusões durantes processos simples deixando o usuário frustrado com a situação.
A utilização de palavras abreviadas ou apenas uma palavra em um botão e a utilização de ícones poderá dar ao usuário uma mensagem mais clara e adequada sobre as funcionalidades de tomar uma ação.
Acessos Facilitados
É muito importante que a interface seja redundante, deixando mais de um caminho possível para que o usuário chegue em seu objetivo ou desfaça alguma ação errada, este papel de guiar de forma fácil o usuário é do profissional de UI Design.
Um exemplo que podemos utilizar e a tela de cadastro que muitos sites utilizam quando um usuário arrasta o mouse pra fora da área de trabalho do browser e a janela modal de fotos do facebook, que podem ser facilmente fechadas utilizando um clique em qualquer parte da tela fora do modal, clique na opção fechar no canto superior e ou apertando o ESC do teclado.
Interação com o usuário
A importância de interação com o usuário é muito importante, a interface deve realizar esta tarefa com muita frequência para que seja mostrado informações sobre ações tomadas e os processos realizados pela aplicação. Exemplos muito simples são as barras de carregamento que podem deixar o usuário esperando o seu carregamento ou finalizar um processo por não ser se o mesmo será carregado.
Prototipagem
A utilização de protótipos, rascunho e wirefrmaes é muito comum para o profissional de UI, para que possa ser desenhado a estrutura inicial do projeto. É a parte essencial, pois através da prototipagem começara a ter uma visão geral do layout e das hierarquias de todo conteúdo da aplicação, a disposição dos elementos da interface e pontos de interação.
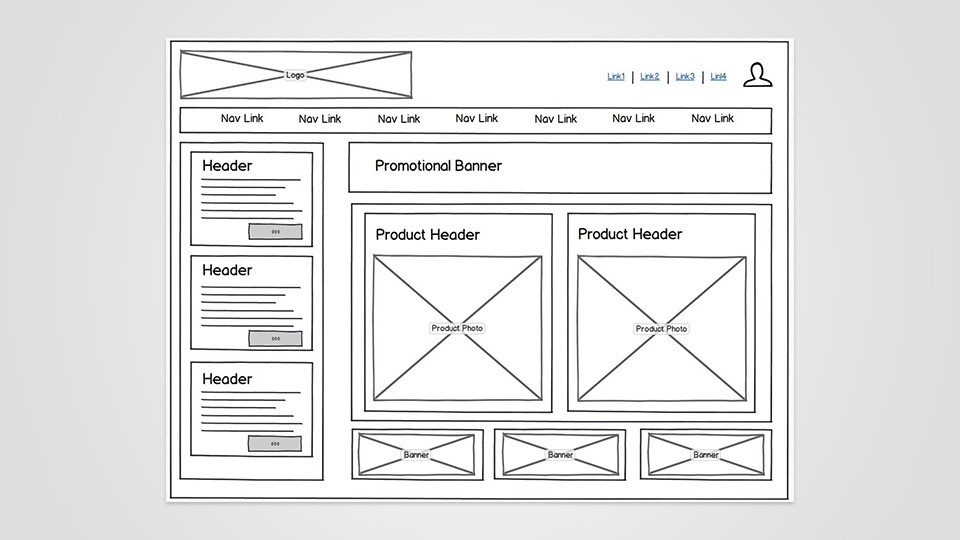
Para trabalhos com HTML, CSS e aplicativos mobile não é aconselhado a criação de interfaces sem que antes o cliente tenha aprovado todo projeto, pois para realizar modificações torna-se muito trabalhoso e demorado.
Referências
Lovi, Rafael. O Que é User Interface (UI)?. Disponível em: < https://www.raffcom.com.br/blog/o-que-e-ui/>. Acesso em 25 abril de 2018.
As Diferenças entre UI Designer e UX Designer. Disponível em: < http://multiad.com.br/design/as-diferencas-entre-ui-designer-e-ux-designer/>. Acesso em 27 abril de 2018.
Rodrigues, Raianne. 5 Dicas: UX e UI design. Disponível em: < https://blog.novatics.com.br/5-dicas-ux-e-ui-design-d787ef46b6b8 >. Acesso em 27 abril de 2018.
Matiola, Willian. O Que é UI Design e UX Design?. Disponível em: < http://designculture.com.br/o-que-e-ui-design-e-ux-design>. Acesso em 28 abril de 2018.
Matiola, Willian. O Que é UI Design e UX Design?. Disponível em: < http://designculture.com.br/o-que-e-ui-design-e-ux-design>. Acesso em 28 abril de 2018.





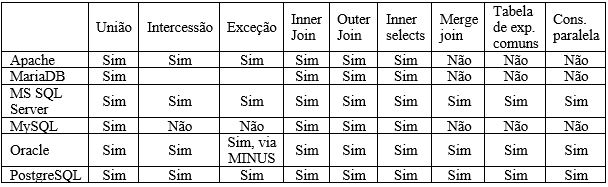
 Algumas definições importantes que devem ser apresentadas de um banco de dados relacional, como sua interface de comunicação o SQL, a sua integridade de dados, ou seja, a forma em que os bancos mantem sua precisão e consistência de dados, assegurada principalmente pelo seu sistema de transações que garantem que “tudo ou nada” seja gravado.
Algumas definições importantes que devem ser apresentadas de um banco de dados relacional, como sua interface de comunicação o SQL, a sua integridade de dados, ou seja, a forma em que os bancos mantem sua precisão e consistência de dados, assegurada principalmente pelo seu sistema de transações que garantem que “tudo ou nada” seja gravado.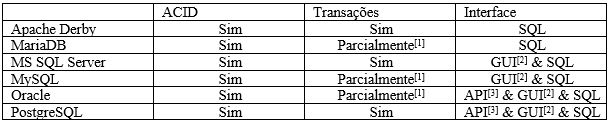
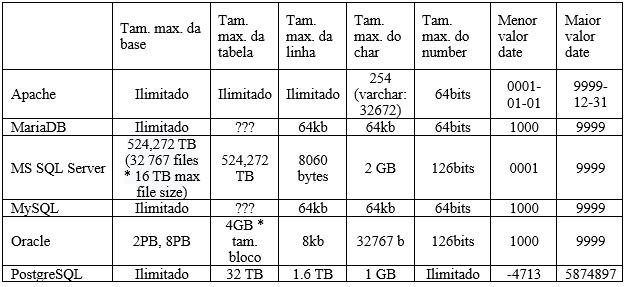

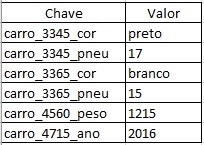
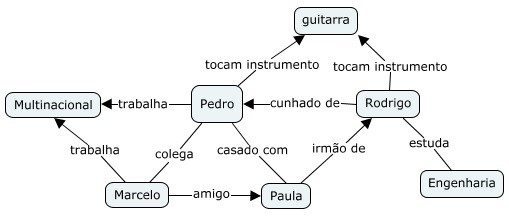
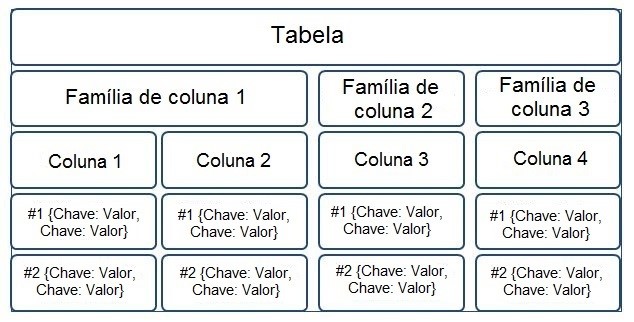
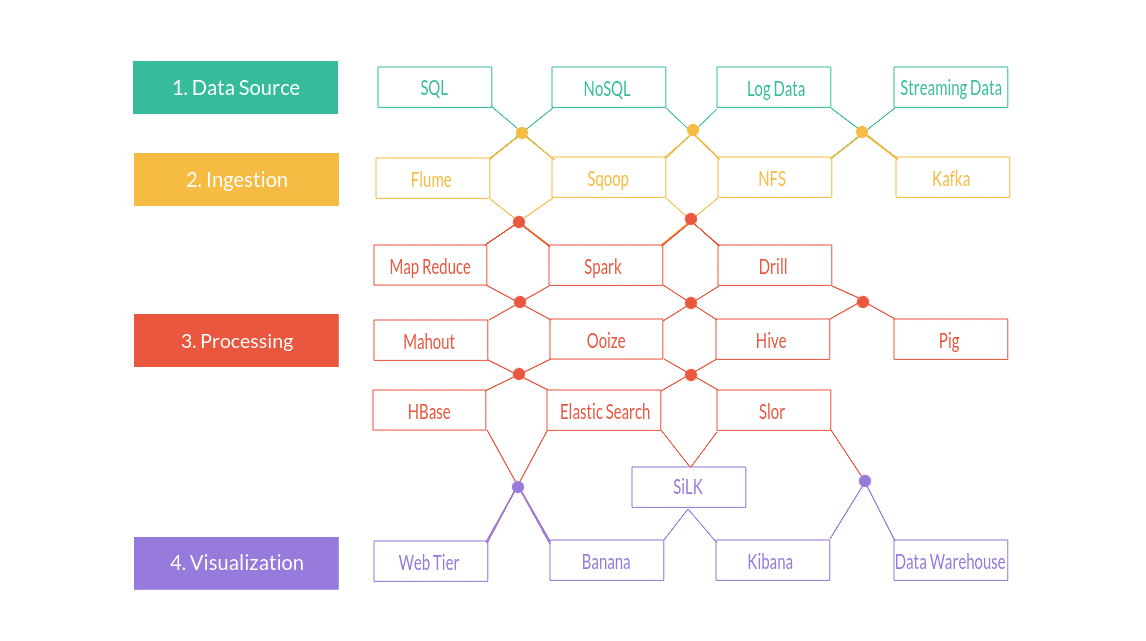
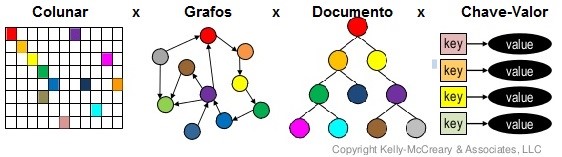 Os bancos de dados NoSQL não são todos iguais. Há grandes diferenças no que se refere como a forma de armazenamento e conceitos de modelagem. Basicamente se subdividem em técnicas de armazenamento diferentes. Há 4 tipos básicos de bancos de dados NoSQL, a seguir eles são descritos.
Os bancos de dados NoSQL não são todos iguais. Há grandes diferenças no que se refere como a forma de armazenamento e conceitos de modelagem. Basicamente se subdividem em técnicas de armazenamento diferentes. Há 4 tipos básicos de bancos de dados NoSQL, a seguir eles são descritos.