

Introdução
O grande volume de dados produzidos pelas empresas nos dias de hoje se tornou um problema para armazenamento, o Hadoop e o Spark surgiram como soluções para essa situação, mas cada um tem sua particularidade.
O hadoop surgiu nos anos 2000 com o foco em dados em disco, por serem mais baratos do que a memória RAM (hoje é mais barata), já a característica principal do Spark é o uso extensivo da memória RAM.
Esse artigo tem como objetivo explicar cada um dos bancos de dados e fazer um comparativo entre eles ajudando a tomar a melhor decisão na hora de escolher.
Spark
O Spark possui uma velocidade de análise e cálculo em memória incrível e de fácil usabilidade, seu código foi aberto em 2010 como projeto da Apache.
O Spark pode acessar dados de diversas fontes como Sistema de Arquivo Distribuído Hadoop (HDFS), bancos de dados NoSQL como Cassandra, e dados
Integrado diversas bibliotecas de níveis elevados, suporte para consultas SQL, streaming de dados, Machini Learning e processamento gráfico.
Módulos construídos no Spark

O Spark permite que aplicações em clusters Hadoop executem até 100 vezes mais rápido em memória e até 10 vezes mais rápido em disco, desenvolver rapidamente aplicações em Java, Scala ou Python. Além disso, vem com um conjunto integrado de mais de 80 operadores de alto nível e pode ser usado de forma interativa para consultar dados diretamente do console.
O Spark é mais adequado usar para os seguintes casos:
- Análise em tempo real
- Resultados instantâneos de analisados
- Operações repetitivas
- Algoritmos de aprendizado de máquina
Algumas empresas que utilizam Spark:

Hadoop
Assim como o Spark o Hadoop também é open-source escrita em JAVA para armazenamento e processamento distribuido , consistindo basicamente no módulo de armazenamento HDFS (hadoop distributed file system) e no módulo de processamento Map Reduce.
Sua estrutura permite o processamento em cluster de grande volume de dados, sua biblioteca é capaz de detectar e resolver possíveis falhas. Os dados são distribuídos quando armazenados e replicados em computadores diferentes. A transferência de dados para computadores diferentes é um dos maiores problemas, por isso foi inspirado no modelo de programação Map Reduce.
O Hadoop é ideal para processamento de grande número dos dados por sua combinação de disponibilidade, durabilidade e escalabilidade de processamento. Ele mantém o alto nível de disponibilidade e durabilidade enquanto continua processando.
Vantagens do Hadoop:
- Velocidade e agilidade maiores
- Complexidade administrativa reduzida
- Integração com outros serviços na nuvem
- Disponibilidade e recuperação de desastres melhoradas
- Capacidade flexível
O Hadoop é mais adequado usar para os seguintes casos:
- Analisando dados arquivados
- Operações de hardware de commodities
- Análise de dados sem pressa
- Processamento de dados lineares
Algumas empresas que utilizam Hadoop:

Hadoop x Spark
A tabela abaixo faz um comparativo do Hadoop com Spark.
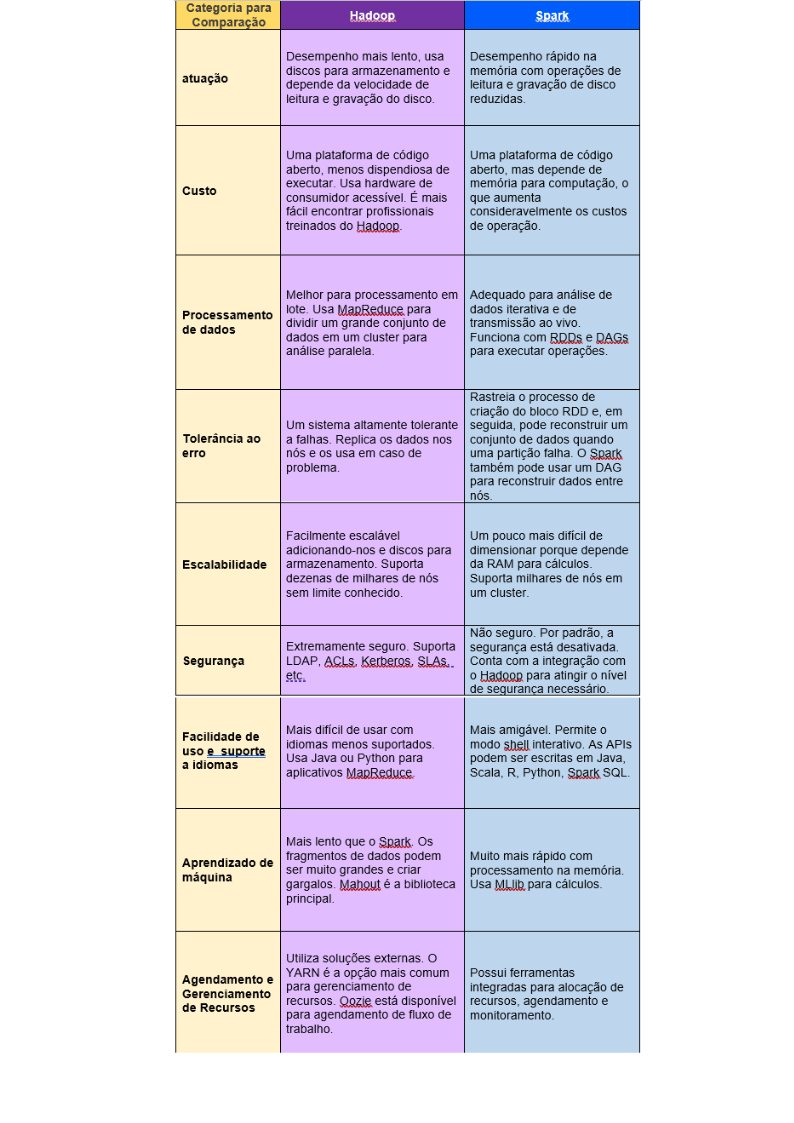
Conclusão
O Spark é recomendado para um número menor de dados, mas que é compatível com o hadoop, e ainda possui um desempenho rápido, análise em tempo real. Alguns pontos que precisam ser melhorados são otimização e segurança.
Já o Hadoop possui um processamento linear de grandes conjuntos de dados seu desempenho é mais lento comparado ao Spark, processamento de dados é em lote fazendo uma análise paralela, um ponto importante que ele é seguro e fácil de usabilidade e de baixo custo.
Autor: Lucas Flores da Silva