Desde o princípio a tecnologia vem passando por crescente transformação. O que antes eram computadores gigantes que ocupavam salas inteiras apenas para fazer simples cálculos, se transformou em dispositivos indispensáveis para o dia-a-dia. São eles: celulares, notebooks, o computador de bordo do carro, a TV smart, o aspirador de pó inteligente, entre muitos outros. Esta grande massa de dispositivos geralmente está conectada à internet. Mas você já parou para pensar como isso funciona? Quais dispositivos podem ser conectados? Eu posso montar um projeto IoT? Aí está mais uma palavra que ouvimos muito hoje em dia. IoT significa Internet of Things (Internet das Coisas), que podemos entender como coisas conectadas na internet.
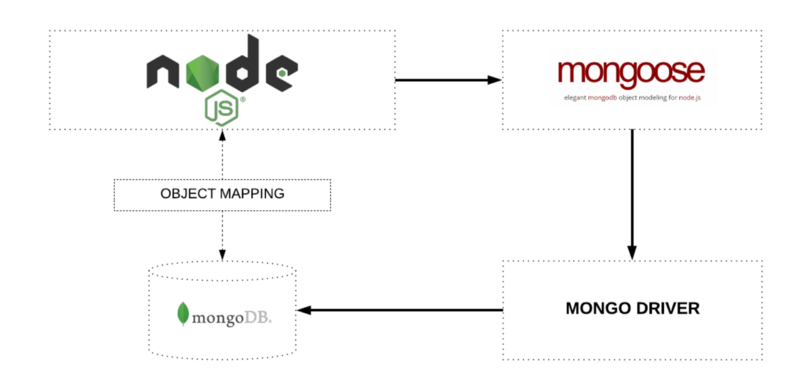
Existem dois tipos de bancos de dados: relacional e não relacional. Os dois bancos podem ser utilizados de formas distintas com diferentes frameworks, podendo-se utilizar o tipo de banco de dados e seu respectivo framework variando entre situações.
O banco de dados relacional trabalhará de forma que tabelas possam se relacionar e formar uma rede de tabelas com dados utilizando frameworks ORM. O banco de dados não relacional em conjunto com o framework ODM deverá ser utilizado para casos com informações menos complexas que exigem todas as informações em um único documento possibilitando uma grande massa de dados.
Com tantos sites e aplicações disponíveis no mundo digital hoje, muitas vezes, para utilizar os serviços e/ou acessar seus conteúdos, é necessário possuir um cadastro. Imagine a quantidade de senhas a serem gerenciadas para cada site e aplicação, se cada vez que queira acessar algo novo, ter que criar um novo cadastro? Ou criar e gerenciar novas senhas? Até porque esse numero elevado de senhas, desgasta o usuário em questão de criatividade, e muitos acabam utilizando senhas fracas, e ou também utilizando a mesma senha para mais de uma aplicação.
Bibliotecas são um conjunto de
funções, métodos e objetos que tem como objetivo facilitar e tornar mais rápido
o desenvolvimento de aplicações, não sendo necessário recriar as funções todas
as vezes que estas forem necessárias, é importante lembrar que uma biblioteca
normalmente é menos complexa, e mais flexível que um framework.
Frameworks
são modelos que implementam ferramentas, funções e padrões em um
projeto de software, que podem abranger projetos web, mobile e desktop,
tanto referente ao front-end quanto o back-end, para as mais variadas aplicabilidades do mercado. Para a definição de um framework em um projeto, é necessário principalmente a boa definição do objetivo do software e as utilidades e facilidades que o framework pode-lhe prover durante todo o ciclo de vida do produto.
Frameworks Back-end
Com
o objetivo de auxiliar a definição de um framework na criação de um
projeto de software, abaixo será listado alguns dos mais reconhecidos
Frameworks do mercado para o desenvolvimento Back-end, para as mais variadas linguagens.
Django
Django
Django é um framework open source baseado na linguagem python que tem um intuito de criar rapidamente aplicações web altamente escaláveis com o máximo de segurança possível, provendo uma arquitetura semelhante ao mvc, o mtv(model-template-view), hoje ele é um dos frameworks mais populares em desenvolvimento phyton junto com o Flask.
Spring Framework
Spring
O Spring é um framework da linguagem Java desenvolvido inicialmente para abstrair a usabilidade do kit de desenvolvimento JEE(Java-enterprise-Edition), focado principalmente na abstração da criação de objetos, conexões(como banco de dados) ou arquivos de sistema, proporcionando um melhor gerenciamento dessas questão deixando o foco do desenvolvedor para o desenvolvimento da regra de negócio.
Ruby on Rails
Rails
Ruby on Rails é um framework Open Source para linguagem Ruby, foi um dos pioneiros no ambiente de frameworks web mudando os padrões do desenvolvimento web e inflamando da participação da comunidade, focado para desenvolver sistemas do zero ajudando principalmente na parte de configuração e na criação de interfaces como CRUD.
ASP .Net Core
Asp .Net core
Asp .net core é o framework da Microsoft que está integrada á plataforma open source .net core, que traz versatilidade e agilidade para o desenvolvimento e implementação por herdar a estrutura de multiplataforma do .net core, aprimorando ainda mais essa característica por trazer opções como gerar o código binário para outro sistema, por exemplo, gerar o código binário para um sistema Linux a partir de um sistema Windows com a mesma facilidade e eficácia se estivesse gerando para o mesmo sistema Windows.
Express Js
Express
Express é um framework para
o ambiente nodeJs, com o foco de facilitar tratamento de requisições e gerenciamento
de rotas, o framework base do Express é bastante minimalista e simples porem é possível
adquirir pacotes de middlewares (Tratativas de requisição) de terceiros para as
mais variadas funcionalidades.
Laravel Framework
Laravel
Laravel é um framework de desenvolvimento rápido para PHP, livre e de código aberto. Cujo o principal objetivo é permitir que você trabalhe de forma estruturada e rápida facilitando o gerenciamento de rotas e criação de templates, porem como outros frameworks ele não é considerado muito flexível.
Conclusão
Todo framework tem suas
qualidades e possíveis defeitos porem para ver o valor e usabilidade de um
framework todo o ambiente e a situação atual deve ser analisada, mas como
pontos gerais o benefício de um framework e a simplificação na codificação e uma
curva possivelmente menor de aprendizado, contra os defeitos de depender do
framework de uma maneira geral e se o framework não for o ideal para sua
aplicação, ela poderá perder um desempenho considerável em seu funcionalidade.
O recurso mais atraente das
interfaces de conversação é a facilidade em que o usuário possui ao utilizar
computadores, smartphones, smartv entre outras inúmeras tecnologias onde a
Inteligência Artificial de conversação pode ser implementada. Para estas
interfaces deverão ser criados modos de interação de fácil operação, já que por
meio do recurso de fala o usuário poderá ter maior liberdade para execução de
outras tarefas que exijam a manipulação de entradas de dados de forma
convencional e ainda, com o uso de sistemas de síntese de fala o usuário poderá
receber informações de forma direta e objetiva.
Uma interface de API de voz
oferece o privilégio de interagir com as máquinas em termos humanos. Pode- se
dizer que é uma mudança de paradigma das comunicações anteriores. Ela permite
que o usuário diga ao software o que fazer, assim, trazendo uma maior inclusão
para pessoas com deficiência sendo elas visuais, locomotoras, dentre outras e
até mesmo para quem busca uma maior automação dos seus aparelhos.
A área de IA com interface de
conversação tem estado em constante alta, nas últimas cinco décadas, sendo
considerada uma tecnologia auxiliar de importante avanço com uma melhor
comunicação Homem-Máquina. Entretanto, anteriormente não era vista como uma
forma confiável de comunicação. Isto porque a capacidade de processamento
existente não era suficiente para fazer reconhecimento de fala em tempo real.
As APIS com interface para comando de
voz
Com o grande avanço da tecnologia de IA de conversação, pode-se citar
algumas APIs principais.
Alexa Voice Service (AVS)
Dispositivos com a Alexa
O Alexa é o serviço de voz criado
pela Amazon em 2014 com base em nuvem que se conecta com o Amazon Echo, uma
nova categoria de dispositivo da varejista online que foi projetado para se
adequar a comandos da sua voz. O Alexa Voice Service (AVS) é o conjunto de
serviços da Amazon construído em torno de seu assistente de IA controlado por
voz para uso doméstico e outros ambientes. O AVS foi introduzido pela primeira
vez com o Echo, o alto-falante inteligente da empresa, que permite a interação
por voz com vários sistemas no ambiente e online. O Alexa está disponível para
um número cada vez maior de outros dispositivos, incluindo smartphones, tablets
e controles remotos.
Ele fornece um conjunto de
recursos internos, chamados de habilidades, sendo elas, tocar músicas de vários
provedores, responder perguntas, fornece previsões do tempo e consultar a
Wikipedia. O Hurricane Center, por exemplo, é uma habilidade do Alexa que
fornece informações constantemente atualizadas sobre sistemas de tempestades,
com base em dados de agências governamentais. Existe também Virtual Librarian é
essencialmente um mecanismo de recomendação que sugere livros, com base em indicações
de prêmios, listas de best-sellers e análises de usuários. O Alexa Skills Kit ,
um kit de desenvolvimento de software ( SDK ), é disponibilizado gratuitamente
para desenvolvedores e as habilidades estão disponíveis para download
instantâneo na Amazon.com
Sendo totalmente integrado ao
ambiente de comércio eletrônico da Amazon, o que significa que torna as compras
rápidas e simples. O sistema pode operar como um hub de automação residencial,
permitindo ao usuário controlar sistemas de aquecimento e iluminação, por
exemplo. O Alexa também se conecta a serviços de mídia de streaming on-line e
suporta If This Then That ( IFTTT ).
O sistema de inteligência
artificial está disponível no Brasil a partir desse ano de 2019, onde possui 3
tipos de caixas de som com os recursos da Alexa.
Cloud Speech-to-Text
Cloud Speech-to-Text
O Cloud Speech-to-Text permite a
fácil integração das tecnologias de reconhecimento de fala do Google nos
aplicativos do desenvolvedor. Com ele os desenvolvedores convertem áudio em
texto ao aplicar modelos de rede neural avançados em uma API fácil de usar. A
API reconhece 120 idiomas e variantes para oferecer suporte à sua base de
usuários global. Ele permite ativar o comando e o controle de voz, transcrever
áudio de call centers e muito mais. Com a tecnologia de machine learming do
Google essa API processa streaming em tempo real ou de áudios pré gravados, ou
seja, ela retorna o texto no momento em que ele é reconhecido. Sendo possível a
analise de áudios de curta ou longa duração
O Speech-to-Text tem três métodos
principais para realizar o reconhecimento de fala. Eles estão listados abaixo:
O reconhecimento síncrono (REST e
gRPC): envia dados de áudio para a API Speech-to-Text, executa o reconhecimento
nesses dados e retorna os resultados depois que todo o áudio foi processado. As
solicitações de reconhecimento síncrono são limitadas a dados de áudio de até
um minuto de duração.
O reconhecimento assíncrono (REST
e gRPC): envia dados de áudio para a API Speech-to-Text e inicia uma operação
de longa duração. Usando essa operação, é possível pesquisar periodicamente
resultados de reconhecimento. As solicitações assíncronas para dados de áudio
de qualquer duração de até 480 minutos.
O reconhecimento de streaming
(somente gRPC): realiza reconhecimento em dados de áudio fornecidos em um
stream gRPC bidirecional. As solicitações de streaming são projetadas para fins
de reconhecimento em tempo real, como captura de áudio ao vivo de um microfone.
O reconhecimento em streaming oferece resultados provisórios enquanto o áudio
está sendo capturado, permitindo que o resultado apareça, por exemplo, enquanto
um usuário ainda está falando.
Siri
Logo Siri
A Siri é um aplicativo
inteligente que auxilia o usuário a realizar tarefas em um aparelho por meio do
recurso de voz. Trata-se de um aplicativo no estilo assistente pessoal
utilizando processamento de linguagem natural para responder perguntas,
executar tarefas e outras atividades. Por possuir uma tecnologia mais refinada,
a Siri não necessita que o usuário diga palavras predeterminadas ou comandos
específicos, já que a assistente consegue compreender frases de forma precisa.
Fundada por Dag Kittlaus, Cheyer
Adam, Tom Gruber e Norman Winarsky, a Siri teve seus primeiros testes
realizados em 2007, foi adquirida pela Apple em abril de 2010, porém, apenas
começou a funcionar em 2011. A Siri
agora conta com o aplicativo de atalhos embutido no IOS 13. A visualização
aprimorada da galeria permite fornecer atalhos pré configurados, esses atalhos
também podem ser combinados com ações de outros aplicativos.
Cortana
Inicialização Cortana
A Cortana é um assistente pessoal
digital que promete auxiliar os usuários de um sistema computacional a realizar
diversas atividades. Não se pode visualizar a Cortana como um simples
assistente que permite a realização de atividades através do comando de voz,
apesar de essa parecer ser sua principal finalidade. Usado corretamente, esse
assistente pode ajudar seu usuário a se manter sempre bem informado,
permitindo-o realizar diversas atividades através de dispositivos e plataformas
distintas.
Muito além do que serviços de
lembrete, ou até mesmo uma interface interativa de pesquisa, a Cortana fornece
uma arquitetura que permite facilmente a incorporação de outras atividades ou
serviços, melhorando assim sua experiência. Trata-se de um recurso capaz de
aprender com o usuário para melhor servi-lo.
Ela permite que o usuário
interaja com o computador por qualquer uma de suas interfaces. Caberá ao
desenvolvedor, dependendo do contexto, determinar qual ação será desencadeada,
ou seja, o usuário pode interagir via texto ou voz e o desenvolvedor decidirá
como irá tratar cada uma das interfaces de entrada. Além de prático e fácil de
utilizar, a Cortana é compatível com qualquer versão do Windows 10 ou superior,
além do Android.
Para o desenvolvedor, é possível
a integração das funcionalidades da Cortana às suas aplicações, podendo essa
interação ocorrer através de solicitações explícitas ou até mesmo com base no
contexto do usuário (análise de seu comportamento).
Ao desenvolvedor, a Cortana
oferece também suporte a uma série de ações pré-determinadas, sendo necessário
somente fornecer à API uma ligação capaz de indicar como sua aplicação deve
responder/completar a ação. O desenvolvedor pode, entretanto, a qualquer momento
personalizar uma ação pré-definida (se julgar necessário), buscando assim
atender às necessidades de sua aplicação.
Watson Text-to-Speech e Speech To Text
Watson
O Watson possui alguns serviços para integrar texto e voz
como o Text to Speech e o Speech to Text.
Onde o Text to Speech transforma
um texto em voz, o Speech to Text transforma voz em texto. Esses
serviços são basicamente simples e diretos de utilizar e não necessitando de
nenhum treinamento adicional. Para a utilização basta instanciá-los no Bluemix
(plataforma em nuvem desenvolvida pela IBM) e escolher o idioma. No caso
do Text to Speech, dependendo do idioma, também é
possível escolher a voz do interlocutor (se masculino ou feminino). Está disponível em 27 vozes (13 neurais e
14 padrão) em 7 idiomas. As vozes selecionadas agora oferecem recursos de
Síntese expressiva e transformação de voz. O uso geral desses serviços conta
com um vocabulário baseado no diálogo cotidiano. Para alguns tipos de
aplicação, esse vocabulário pode não ser suficiente e requerer refinamentos que
o ajustem ao domínio da aplicação. Nesse caso, é possível ajustar o modelo de
acordo com os termos e pronúncias utilizados naquele domínio.
Com isso pode se verificar a
importância que as APIs vem possuindo nos últimos anos, onde podemos ver essa
inteligência tomando amplamente destaque no mercado. Com este artigo foi
possível identificar algumas das principais e mais desenvolvidas APIs de Voz,
mais utilizadas em equipamentos do dia a dias como smartphones e smartvs.
O reconhecimento de voz contínuo
é o mais complexo e difícil de ser implementado, pois deve ser capaz de lidar
com todas as características e vícios de linguagem, como regionalidade e gírias
tão utilizadas frequentemente, de forma natural. Vale ressaltar que as APIs
citadas acima trabalham de forma online, sendo assim, para trabalhos futuros
estarão direcionadas as pesquisas para APIs que utilizam o reconhecimento de
voz de forma offline, para assim, trazer uma maior automação dos equipamentos
mesmo desprovidos de internet no momento.
Autora: Laís
Fochezatto Sabedot
Referências
Y. Dong and L.
Deng, Automatic Speech Recognition. London: Springer-Verlag, 2015.
V. F. S.
Alencar. 2005. Atributos e Domínios de Interpolação Eficientes em
Reconhecimento de Voz Distribuído. Master’s thesis. Pontifícia Universidade
Católica do Rio de Janeiro, Rio de Janeiro, Brasil.l
Gigantescas
ondas de informações, dos mais variados tipos são lançadas diariamente na
internet – o tal chamado “Fenômeno BIG DATA”.
E este volume de dados cresce em tal proporção que, sistemas de busca
convencionais não estão mais sendo capazes de gerir e varrer tantas
informações, prejudicando a qualidade com que os dados são apresentados aos
usuários.
Em busca de solucionar – ou pelo menos amenizar – este problema, portais de venda e de conteúdo têm desprendido esforços cada vez maiores para tornar mais assertiva suas campanhas de maketing, através dos chamados “Sistemas de Recomendação (SR)”. Mas para entender como funcionam estes sistemas, é necessário conhecer sobre um assunto em alta na atualidade – A Inteligência Artifical (IA).
Inteligência Artificial: O passo humano nas máquinas
Segundo
Ribeiro (2010, p.8), “a inteligência artificial é uma ciência multidisciplinar
que busca desenvolver e aplicar técnicas computacionais que simulem o
comportamento humano em atividades específicas”. De acordo com Lima, Pinheiro e
Santos (2014), os primeiros estudos sobre inteligência artificial surgiram na
década de 1940, marcada pela Segunda Guerra Mundial, onde houve a necessidade
de desenvolver métodos tecnológicos voltados para análise balística, quebra de
códigos e cálculos para projetos de arma nucleares.
A IA possibilita que máquinas aprendam com experiências, se ajustem a entradas de dados novas e executem tarefas similar a um ser humano. Tudo isso depende do deep learning e do processamento de linguagem natural, tecnologias das quais permitem que os computadores sejam treinados e possam reconhecer padrões nos dados apresentados a eles.
Reconhecimento de Padrões
A IA
faz uso do reconhecimento de padrões para analisar e classificar dados,
agrupando-os por similaridade, podendo ser identificadas preliminarmente ou
dedutivamente. O reconhecimento de padrões é uma tarefa trivial ao ser humano,
mas que se torna custosa às máquinas, uma vez que ainda não se conseguiu
desenvolver um equipamento ou sistema com capacidade de reconhecimento à altura
do cérebro humano.
O trabalho de reconhecer padrões é que permite identificar em qual grupo (ou classe) um dado novo pertence. Este tipo de trabalho é que permite que sistemas de recomendação, muito utilizados pelos e-commerces, ofertem produtos que os usuários estejam planejando adquirir, sem ao menos terem acessado o site do portal de vendas.
Mas, e como são identificados estes padrões???
Para
identificar estes padrões dois tipos de métodos são mais utilizados hoje: o
supervisionado e o não-supervisionado.
Método Supervisionado: É dado à máquina um
conjunto de dados do qual já se sabe qual é a saída correta, e que deve ser
semelhante ao grupo, percebendo a idéia de que saída e entrada possuem uma
relação. É como se existisse um “professor” que ensinasse qual o tipo de
comportamento que deveria ser exibido em cada situação.
Método Não-Supervisionado: Esse método, ao
contrário do supervisionado, não possui uma rotulação prévia (não existe um
“professor”). Conforme os dados forem sendo apresentados, a máquina precisa
descobrir sozinha relações, padrões e regularidades e codificá-las nas saídas,
criando grupos (processo chamado de clusterização).
Exemplo de Clusterização
E-business têm se valido destas ferramentas para desenvolver sistemas que conseguem identificar o perfil do usuário que está acessando seu portal de vendas e através de um cruzamento de dados com outros perfis de usuários similares, estão podendo direcionar sua força de marketing de forma mais assertiva. É o caso dos Sistemas de Recomendação.
O que é um Sistema de Recomendação (SR)?
Sistemas
de Recomendação são, basicamente, um conjunto de algoritmos que utilizam
técnicas de Aprendizagem de Máquinas (AM) e Recuperação de Informação (RI) para
gerar recomendações baseadas em filtragens. Estas filtragens podem ser do tipo:
colaborativa, baseada em conteúdo ou híbrida.
Filtragem
Colaborativa: É uma técnica para recomendação baseada no
conhecimento coletivo, ou seja, baseia-se nas preferências dos usuários acerca
dos itens que compõem um determinado catálogo do sistema;
Filtragem
Baseada em Conteúdo: Diferente da Filtragem Colaborativa, a
Filtragem Baseada em Conteúdo leva em consideração os atributos dos itens para identificar
similaridades entre o perfil do usuário e o perfil do item. Basicamente ela se
baseia em itens que o usuário já tenha demonstrado interesse no passado para
recomendar.
Filtragem
Híbrida: Esta uma “mistura” das filtragens anteriores, buscando combinar
as vantagens das duas e atenuar as desvantagens das mesmas.
Os SR’s têm então o objetivo de gerar recomendações válidas aos usuários de itens que possam os interessar, como por exemplo, sugestão de livros, filmes, amigos em redes sociais, etc. Para isso, um dos principais conceitos utilizados pelos SR’s é a similaridade, identificada pelo reconhecimento de padrões abordado anteriormente neste artigo. Para isso, os algoritmos mais utilizados são o KNN (K-Nearest Neighbors), Árvore de Decisão, Redes Bayesianas e Redes Neurais. Neste artigo, nossa ênfase se dará em cima das Redes Neurais, explicadas a seguir.
RNA – Redes Neurais Artificiais
Uma RNA compreende um conjunto de elementos de
processamento conectados e organizados em camadas. Um dos modelos de RNAs é
disposto em camadas, onde as unidades são ordenadas e classificadas pela sua
topologia e a propagação natural da informação é da camada de entrada para a de
saída, sem realimentação para as unidades anteriores.
As entradas são processadas e transformadas por
uma função de ativação até que um determinado critério de parada seja atendido
(quantidade de ciclos (épocas) ou erro mínimo), obtendo os pesos sinápticos que
melhor se ajustem aos padrões de entrada. Nesse estágio, pode-se dizer que a
rede está treinada. Contudo, a rede neural pode apresentar ou não a capacidade
de generalização – permitir a classificação correta de padrões já conhecidos,
mas que não faziam parte do conjunto de treinamento.
As RNA’s podem ser utilizadas na recomendação de sistemas de Recomendação baseadas em modelos. As RNA’s podem combinar vários módulos de recomendações ou várias fontes de dados, podendo ser exemplificado como na construção de um sistema de recomendação para TV a partir de quatro fontes de dados diferentes: informações de comunidades, contexto de exibição de programas, perfil de usuários e metadados dos programas.
Concluindo…
Neste viés, as RNA’s estão apresentando vantagens superiores sobre as demais técnicas, principalmente pelo fato de trabalharem muito bem com grandes volumes de dados, reduzindo a dimensionalidade sem perder representatividade da informação original. Outra vantagem é conseguir trabalhar com dados dinâmicos (ou de curto prazo), se comparados à algoritmos clássicos e também por conseguir a interação entre usuário e conteúdo, representando os dados de forma não-linear, permitindo que a generalização não seja tão limitada quanto demais métodos (Fatoração de Matrizes, por exemplo).
Autor: Valmor Marchi
Referências
FERNANDES, Marcela Mayara Barbosa; SEVERINO, Áxel Douglas Santos; FERREIRA, Patrick Pierre Fernandes. SISTEMAS DE RECOMENDAÇÃO WEB UTILIZANDO A REDE NEURAL ARTIFICIAL DO TIPO PERCEPTRON. 2014. Disponível em: <http://www.fepeg2014.unimontes.br/sites/default/files/resumos/arquivo_pdf_anais/artigo_-_sistemas_de_recomendacao_utilizando_uma_rede_neural_artificial_perceptron_1.pdf>. Acesso em: 14 nov. 2019.
LIMA, I.; SANTOS, F.;
PINHEIRO, C. Inteligência Artificial.
Rio de Janeiro: Elsevier, 2014.
RIBEIRO, R. Uma Introdução à Inteligência
Computacional: Fundamentos, Ferramentas e Aplicações. Rio de Janeiro:
IST-Rio, 2010.
SANTANA,
Marlesson. Deep
Learning para Sistemas de Recomendação (Parte 1) — Introdução. 2018.
Disponível em: <https://medium.com/data-hackers/deep-learning-para-sistemas-de-recomenda%C3%A7%C3%A3o-parte-1-introdu%C3%A7%C3%A3o-b19a896c471e>.
Acesso em: 16 nov. 2019.
Material Design nasceu da coleta de informações e conhecimentos que se transformaram em diretrizes para aprimorar a relação homem-máquina, isso tornou-se em um sistema de desenvolvimento para interface do usuário, definido por um conjunto de propriedades que qualquer objeto dentro do sistema deve aderir.
É chamado Material, pois a ideia é trazer um material sólido para a interface virtual, todos os objetos têm uma altura definida, essa altura ajuda na interação com o usuário dando dicas visuais e também é responsável pelas sombras geradas, assim dando um efeito mais natural aos olhos.
As diretrizes do material design não só criam uma experiência prazerosa visualmente, mas também proveem consistência através dos dispositivos e aplicações e dicas do que virá a acontecer na tela.
Pense como um Engine de um jogo, onde toda a física, texturas, iluminação, animações são delimitadas pelas propriedades da Engine. O mesmo vale para o Material Design. Existe um ambiente 3D onde todos os elementos funcionam de formas restringidas pelas propriedades e diretrizes definidas pela Google.
No Material Design existem as propriedades físicas, propriedades de transformação e propriedades de movimento, estas propriedades são combinadas para temos componentes com um comportamento parecido com papel que pode mudar dinamicamente dependendo do seu uso.
Limitações:
Existem algumas limitações impostas pela Google que devem ser respeitadas:
Materiais são sólidos e não podem atravessar um ao outro
Materiais não podem ser curvados ou dobrados
Todos os materiais tem a mesma espessura, definida pelo Google como 1DP (medida utilizada no desenvolvimento Android, que diferente do pixel, vai apresentar o mesmo resultado em diferentes resoluções).
Sombra:
A Sombra é uma das maneiras mais rápidas de identificarmos onde um objeto se localiza num espaço 3D, ou seja, a distância relativa entre eles. A sombra também nos ajuda a identificar movimento, que como estamos em um ambiente 3D pode ser relacionada a altura do material.
Movimentos:
No Material Design movimentos nos trazem um senso de objetivo. Objetos podem ser movidos livremente, e especialmente em relação a altura como mencionado acima. Essa altura é bastante utilizada como uma dica visual para indicar o local de interação do usuário. Isso é implementado usando “Dynamic Elevation Offset“, que é a posição de destino do objeto relativo a posição de repouso dele mesmo.
Por exemplo todos os componentes que sobem num clique, tem a mesma mudança de elevação relativos aos suas posições de repouso. O objetivo é que todos os movimentos do mesmo tipo possam ser agrupados, gerando consistência.
Animações:
O Google identificou que mudanças abruptas de velocidade ou direção são brutas e causam distrações indesejadas. Com isso muitas das animações contam com um processo de aceleração, e para se tornar mais próxima ao mundo real se faz uso de aceleração assimétrica.
Aceleração assimétrica pode indicar o ‘peso’ de um objeto. Objetos menores ou mais leves podem se movimentar mais rápido porque eles precisam de menos “força”, e objetos mais pesados podem demorar um pouco para acelerar porque precisam de mais “forca”.
A transição entre dois estados visuais deve ser clara, suave e de pouco esforço. Uma transição bem feita indica ao usuário onde ele deve focar a sua atenção. O Google chama isso de “Visual Continuity”, tem as seguintes diretrizes para ser consideradas:
Onde o usuário deve focar, quais elementos e movimentos apoiam esse objetivo.
Transições devem estar conectadas visualmente, através de elementos persistentes e cor.
Usar os movimentos com precisão, isso traz clareza e suavidade pra transição.
Quando fazendo uma transição o Material Design considera a ordem o timing dos elementos, isso transmite qual conteúdo é mais importante, criando um caminho para o olho do usuário seguir, o Google chama isso de ” Hierarchical Timing” e deve ser sempre usado para direcionar a atenção do usuário e não deixar todas as transações ocorrerem ao mesmo tempo sem indicativos do que é mais importante.
Quando as transações de elementos são coordenadas, isso cria uma facilidade para o usuário entender o aplicativo, os destinos dos elementos na transação devem fazer sentido e ser o mais ordenados possível, isso é chamado de “Consistent Choreography”. Para obter esse resultado é indicado evitar movimentos conflitosos ou caminhos sobrepostos, a altura em que os objetos de movimentam e porquê fazem isso e indicam até visualizar se o traçando o caminho de todos os objetos movimentados obtemos uma imagem limpa e organizada.
Material Design imita a realidade, traz um sistema de design simples para um ambiente digital 3D com parâmetros e diretrizes bem definidos. Intuitivamente transmite como uma interface deveria funcionar se fosse feita de papel digital. Essa intuição auxilia no rápido entendimento e reconhecimento da interface, com o menor esforço do usuário.
Para saber mais sobre o Material Design e começar a utilizado segue o site oficial, que conta com uma vasta documentação e representações visuais para melhor entender alguns destes conceitos: https://material.io/
Também interessante ver dos próprios criadores alguns comentários da criação e desenvolvimento, segue vídeo de apresentação do Google sobre o tema: https://www.youtube.com/watch?v=rrT6v5sOwJg
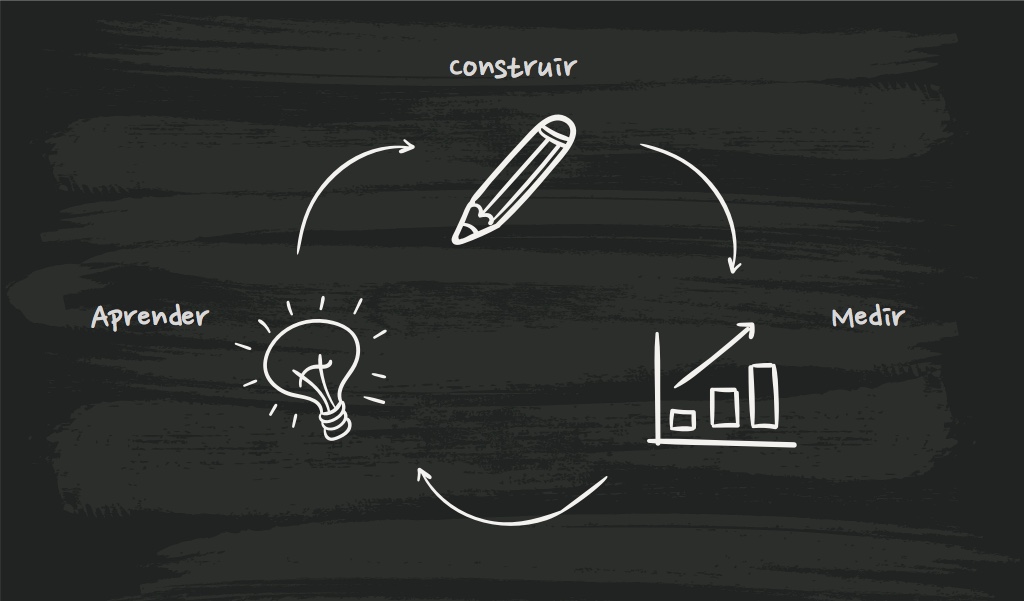
Startups são empresas em fase inicial que desenvolvem produtos ou serviços inovadores, com potencial de rápido crescimento. Neste contexto de empreendedorismo, principalmente abordando o tema startups, temos o conceito de MVP que no português significa Mínimo Produto Viável.
O MVP é a versão mais simples de um produto que pode ser lançado com uma quantidade mínima de esforço e desenvolvimento. Um MVP ajuda os empreendedores a iniciarem um processo de aprendizagem, poupando tempo e esforços.
O MVP pode ser uma das primeiras etapas do processo empreendedor. Eleger um MVP significa observar e coletar dados sobre clientes e criar situações práticas de negócio que façam com que a startup aprenda e se molde rapidamente com o intuito de lançar uma solução inovadora.
A prática ajuda a investir em um produto certeiro, que seja realmente útil para o seu público alvo. Além disso, depois de algum tempo de prática será possível prever os fatos antes que eles aconteçam, lançar novidades antes que seja tarde demais.
Desenvolver um MVP para ideia de negócio não é garantia de sucesso. Eles são projetados para testar as suposições de um problema que queremos resolver sem que haja muitos investimentos. Para tanto, existem alguns tipos de MVP para auxiliar a escolha da estratégia inicial.
Tipos de MVP
Papel
Podem ser desenhos feitos à mão, de uma interface para usar como protótipo, ou exemplos ilustrados de um projeto. Fáceis de fazer, visuais que criam entendimento compartilhado. Este tipo de MVP possui algumas limitações, a sua interação é limitada e não testa usabilidade ou hipóteses. Alguns exemplos são diagramas ou esboços.
Protótipo Interativo
Estes podem ser representados por maquetes interativas, clicáveis. Testa designs e usabilidades, itera soluções rapidamente e ainda usa entrevistas com clientes. Este não testa hipóteses e nem tecnologias de apoio. Exemplos são HTMLs ou maquetes clicáveis, ou ainda vídeos.
Concierge
É um serviço pessoal, em vez de um produto, que manualmente guia o cliente pelo processo, usando os mesmos passos propostos para resolver o problema do cliente no produto digital. Reduz a complexidade, suporta pesquisa generativa, valida suposições qualitativamente com baixo investimento. Seus contras são a escalabilidade limitada, é manual e tem uso intensivo de recursos, o cliente sabe do envolvimento humano.
Mágico de Oz
Este é o produto real em operação. Apesar de nos bastidores, todas as funções são executadas manualmente sem o conhecimento da pessoa que está usando o produto. Uma solução em operação da perspectiva do cliente, uma pessoa no papel do mágico pode conseguir envolvimentos mais próximos. Possibilita pesquisa de avaliação para preço e validação da proposta de valor. Alguns dos contras podem ser a escalabilidade limitada devido a um alto comprometimento de recursos.
Micronicho
Micronicho consiste em reduzir todas as features do produto ao mínimo, a fim de descobrir se os clientes estão interessados ou dispostos a pagar por ele. Um teste altamente focado, dedicado a qualquer tópico específico, exige mínimo esforço. Um dos contras seria a necessidade de investimento financeiro, pois um dos exemplos deste seria a disponibilização de uma página web simples com o produto oferecido.
Software em Operação
Como o próprio nome deste MVP já diz, trata-se de oferecer o produto em operação funcionando plenamente para resolver o problema de um cliente, equipado para medir comportamento de cliente e interações. Alguns dos benefícios são testar hipóteses em um ambiente real, valida suposições qualitativamente. Porém este é caro, precisa de investimento em pessoas e ferramentas.
Empresas que utilizaram MVP
Facebook
A rede social foi testada, inicialmente, para dentro dos muros da Universidade de Harvard. O período em que a rede atingia apenas os alunos da comunidade universitária foi importante para que o jovem Mark promovesse alterações fundamentais, em linha com o que foi se revelando necessário ao longo do processo de validação.
Groupon
A primeira versão do Groupon era um site extremamente simples, feito em wordpress e que gerava cupons em pdf, os quais eram enviados de forma manual a cada interessado.
Apple
O iPhone 1 era o típico exemplo de MVP. O aparelho não possuía algumas funções básicas, como copiar e colar, além de exigir download obrigatório do iTunes para ativação. O objetivo aqui era claramente segurar algumas funcionalidades para que fossem lançadas nas versões seguintes do equipamento, gerando ansiedade e euforia entre os clientes.
Foursquare
Antes de ir a campo, o serviço de localização coletou depoimentos e sugestões de possíveis usuários, por meio do Google Docs, além de disponibilizar uma versão mais restrita do produto a um grupo seleto de futuros clientes.
Principal Framework CSS usado em front-end de aplicações web, com seus recursos, tornam o desenvolvimento de páginas mais fácil, páginas que se adaptam a diversos tamanhos de tela.
Conceito
Bootstrap é um conjunto de componentes correlacionados para ajudar a desenvolver interface com o usuário de forma ágil e fácil. Foi criado em agosto de 2011 pelos desenvolvedores do Twitter, Mark Otto e Jacob Thorton. Tem como objetivo central fornecer ao usuário uma facilidade de desenvolvimento de layouts pré-configurados, tanto para questão de produtividade como também da questão da responsividade.
Customização, responsivo e documentação são as principais características do Bootstrap. Pois a customização é rápida e fácil, responsividade torna o site mais responsivo e a documentação conforme o site do desenvolvedor, mostra que é bem simples e prático de aprender tornando a implementação fácil. Geralmente usado em frond-end, mas atualmente é utilizado em back-end, pois suas ferramentas visuais tornam o visual dos projetos avançados mais aperfeiçoado. Dessa forma, o usuário fica mais familiarizado com o sistema.
Incluso em seu conjunto de recursos, se encontram o HTML 5, CSS 3, Jquery, Node, JavaScript, Ajax. Dessa forma, ao baixar o pacote Bootstrap, não será mais preciso baixar os plug-ins do Jquery por exemplo, pois já faz parte do pacote do Bootstrap.
Rápido
Bootstrap é rápido por quatro motivos:
Seus arquivos tem um tamanho bem pequeno.
js tem no máximo 83kb;
css tem no máximo 98kb
webfont tem no máximo 144kb.
Carrega só o que precisa, somente o que for utilizado no projeto.
Escrever menos código, não precisará definir todo o layout do formulário, pois irá usar classes pré-definidas e melhorar o layout do formulário sem precisar codificar mais nada por exemplo.
Utiliza o sistema de Grids, principal enfoco do Bootstrap, por causa das 12 colunas que se trabalha de forma dinamizada da ferramenta.
Fases do Bootstrap:
Versão 1 – Somente disposto para facilitar o desenvolvimento para desktops. Não tinha os conceitos ligados a responsividade de acordo com outros dispositivos, exemplo tablets, smartphones.
Versão 2 – Desenvolvimento para desktop com adaptação para tablete e por fim smartphones. Foi implementado a responsividade para dispositivos móveis.
Versão 3 – Surgiu o conceito de mobile first, que é justamente a questão da responsividade inicial para mobile para posteriormente adaptação dos desktops. Inverso da segunda versão.
Versão 4 – Realizado a mudança do modelo Less para o Sass, deixando a compilação mais rápida. Fim do suporte para IE8 e lançamento do Bootstrap themes.
Sistema de grade (Grids System) é responsivel e permite até 12 colunas através da página. Tem 4 tipos de classes, dependendo do dispositivo e pode ser ntegrado com outro para criar layouts flexíveis. O layout de sites que são visualizados tanto em navegadores de desktops ou mobile, são de extrema importância, pois o uso das grids, tem o papel de ajustar o layout conforme o tamanho da tela. Assim, tornando sistemas de grade útil.
Bootstrap fornece ferramentas para a construção de sites e aplicações modernas, agregando recursos dinâmicos. Sendo uma ferramenta gratuita e de fácil acesso, vale muito a pena o uso de Bootstrap em projetos mais avançados.
Autor Douglas Beux
Fontes:
Baseado em http://www.ericplatas.com.br/artigos/introducao-bootstrap-framework/.
Adaptado de https://imasters.com.br/design-ux/design-responsivo/7-razoes-para-desenvolver-seus-web-designs-no-bootstrap/?trace=1519021197&source=single.
Adaptado de https://www.youtube.com/watch?v=0o2GWZ0uUeY&t=1839s.
No passado usavam-se sites estáticos, sem iteração com os usuários, porém logo surgiram aplicações Web, essas sim necessitavam de recursos e o nível de complexidade aumentou.
Inicialmente usou-se JavaScript/Jquery mas nem sempre ela garantia a alta produtividade e a facilidade na manutenção de código.
O que é o Angular JS?
AngularJS é um framework front-end que auxilia a criação de Single Page Aplications(SPA), e vem ganhando destaque desde de seu surgimento em 2011-2012 por Misko Every e Adam Ebrons, cujo objetivo era facilitar a criação de aplicações web. É baseado em um modelo MVW(Model View Whatever), uma brincadeira da Google dando um ponto final a uma longa discussão entre a comunidade de desenvolvedores que não chegavam em um acordo sobre o modelo utilizado cujos principais eram: MVC(Model View Controller), MVP(Model View Presenter) e MVVM(Model View View Model).
O começo:
Angular JS, foi desenvolvido por Misko Hevery em um projeto pessoal com o objetivo de aprimorar o desempenho de aplicações Web. Pouco tempo depois, Hevery entrou para o Google e aplicou sua framework no projeto Google feedback, diminuindo o número de linhas do código e aumentou sua performance. Google feedback e uma ferramenta que está presente em todos os produtos da Google como: Google+, Chrome, Hangouts entre outros, onde você pode enviar impressões do que estão acontecendo nos produtos como: erros, críticas e com isso o suporte vai poder observar se usuário final está gostando ou não dos produtos. Atualmente, o Google e o principal contribuinte para o código do AngularJs.
O AngularJS veio para padronizar a estrutura de desenvolvimento de aplicações para web, fornecendo um template com base nos padrões client-side.
Quem usa AngularJS:
Muitos clientes de grande porte usam Angular, devido a sua performance com simplicidade, os sites possuem o framework Angular: Airlines, paypal, cvs shop ,Micro Soft, Google Play,ABC News, San Disk, Trello.
Por que usar?
Usar este framework facilita a produtividade pelo reuso de código. Também visando a continuidade, hoje o mesmo está sendo mantido pelo Google, tendo como a certeza que ele não deixará o mercado tão cedo, tendo esforços de grandes equipes na linha de desenvolvimento, o angular segue muito bem o mantra da produtividade. Por ser orientado a componentes, é muito rápido e fácil programar com ele.
Praticamente qualquer coisa que se precisa já tem pronta por aí nos milhares de repositórios do GitHub. Existe inclusive um site que reúne mais de 2000 módulos open-source para facilitar a busca https://angular.io/guide/ngmodules. Possui comunidade Sólida o Repositório do Angular no GitHub tem 49 mil estrelas e mais de mil contribuintes, além de mais que 150 mil repositórios com scripts que utilizam a tecnologia.
No Stack Overflow, a maior comunidade de perguntas e respostas do mundo, temos quase 180 mil perguntas. Caso o interesse seja em vídeos sobre o assunto, o YouTube nos dá uma marca impressionante de 470 mil vídeos. O interesse da comunidade tem subido exponencialmente nos últimos anos, de acordo com o Google.
O Angular está sendo conhecido pela internet também pela sua curva de aprendizado. Em poucos minutos você aprende seus conceitos e já está desenvolvendo seu primeiro app.
O AngularJS usa em sua arquitetura o modo MVC (Model View Controller), que é um padrão para dividir uma aplicação em diferentes partes (modelo, visão e controle), cada uma com suas respectivas responsabilidades. Contando com três camadas de comunicação, que são elas:
Controller : Sempre que você pensar em manipulação de dados, pense em model. Ele é responsável pela leitura e escrita de dados, e também de suas validações.
View: Simples: a camada de interação com o usuário. Ela apenas faz a exibição dos dado.
O responsável por receber todas as requisições do usuário. Seus métodos chamados actions são responsáveis por uma página, controlando qual model usar e qual view será mostrado ao usuário.
Um exemplo disso seria um restaurante, o Controller é o pessoal da cozinha que prepara o prato, mas não sabe para quem irá fazer, a View é o cliente que apenas recebe o prato e consome, mas não sabe quem fez, o Scope é como se fosse o garçom que faz o meio de campo entre Controller e View.
Outro recurso interessante para economia de dados e melhor performance é carregar apenas uma página principal, recursos de aplicação e outras páginas são carregadas por demanda, deixando a experiência mais fluida. Essa funcionalidade é conhecida como Route Engine. Este mecanismo de rotas é disponibilizado com o nome de angular-route.js.
A utilização deste framework torna a aplicação mais rápida e mais enxuta do que as outras formas de desenvolver interface para web.
Desde a década de 60 é investido em estudos em tecnologias que tenham a mesma capacidade dos seres humanos, de pensar e raciocinar sobre diversos assuntos, que possam tomar decisões baseadas na bagagem emocional e social, no entanto, estes estudos tiveram altos e baixos e poucos resultados significativos foram obtidos, mas no início dos anos 2000 essa tecnologia passou a ganhar uma maior notoriedade. A IBM, girante da tecnologia mundial, foi uma das pioneiras a lançar no mercado uma tecnologia de computação cognitiva, o IBM Watson, um software com capacidade de tomar decisões baseadas no conhecimento adquirido.
O IBM Watson foi criado em 2003 e recebeu este nome em homenagem ao fundador da IBM, o empresário norte-americano Thomas Watson. O Watson ganhou uma maior notoriedade somente em fevereiro de 2011 em um famoso show de perguntas e respostas de conhecimento geral nos Estados Unidos chamado Jeopardy, no qual venceu a disputa. Esta tecnologia de computação cognitiva chegou ao Brasil em 2014, já com APIs traduzidas para a língua portuguesa.
O data center da IBM que hospeda o software do Watson é composto por duas grandes unidades, divididas cada uma em cinco torres, com 10 servidores IBM Power750. Tudo isso equivale a 2.800 computadores juntos. A memória é de 15 trilhões de bytes.
O Watson pode interpretar dados não estruturados vindos da web em qualquer formato, seja vídeo, texto ou foto, como faz um ser humano, mas com a velocidade de uma máquina com tecnologia de ponta. É daí que vem o nome de computação cognitiva, já que a cognição é o processo por meio do qual nós adquirimos conhecimentos a partir dos nossos sentidos.
À sua maneira, o IBM Watson pode pensar, graças a algoritmos complexos de inteligência artificial baseados em redes neurais e na tecnologia de aprendizagem chamada deep learning. Por dia, 2,5 bilhões de gigabytes de informações da web são processadas para que ele se torne ainda melhor.
Conforme os dados vão sendo lançadas ao IBM Watson, o sistema vai aprendendo cada vez mais sobre o complexo processamento de linguagem. Ele varia de idioma para idioma, mas se baseia em três pilares: gramática, estrutura e relação de palavras. É por isso que o Watson sabe que a manga da camisa não é uma fruta e o banco da praça não é uma instituição financeira.
Toda a análise é criada com base em computação probabilística, em que o resultado varia em função de um espectro e não simplesmente de parâmetros de “sim ou não” e “se isso, então aquilo”, como acontece em sistemas menos complexos.
Atualmente, a IBM oferece mais de 30 APIs (Interface de Programação de Aplicação) do IBM Watson a desenvolvedores. Com isso, a expertise de computação cognitiva é oferecida para empresas e startups que queriam criar um produto com inteligência artificial. Hoje, o Watson já tem aplicações importantes em quase 20 segmentos, incluindo saúde, advocacia, gastronomia e educação.
As APIs fornecidas pela IBM, disponíveis no site Bluemix, são na sua grande maioria gratuitas e podem ser utilizadas por desenvolvedores, no entanto, a partir do momento que há ganhos em escala com as aplicações, esses recursos passam a ser cobrados.
Dentre as diversas APIs oferecidas pela IBM na plataforma do Watson, foram listadas a seguir 5 exemplos que podem ser facilmente utilizadas, com uma breve descrição de cada uma.
Text to Speech
Transforma texto em áudio com entonação e cadência apropriada. Está disponível em diverso idiomas. Em português, há uma versão com voz feminina disponível, chamada de Isabela. Não tem custo para até 10 mil caracteres por mês.
Speech to Text
O serviço converte a fala humana para texto e pode ser usado para toda aplicação que precisa de uma ponte entre a voz e um documento escrito, incluindo sistemas de controle, transcrição de entrevistas ou conferências telefônicas e ditar e-mails e notas. A ferramenta usa inteligência de máquinas combinadas com informações de gramática e estruturas de linguagem com arquivos de áudio por gerar transcrições mais precisas. O serviço está disponível em Inglês (EUA), inglês (RU), japonês, árabe (MSA), mandarim, português (Brasil), espanhol, francês, coreano. O serviço é gratuito para até 100 minutos de áudio por mês.
Tone Analyser
Este serviço pode captar diversas informações de sentimento por meio da entonação de um texto, como: alegria, tristeza, raiva, etc. Essa entonação pode impactar a efetividade de uma comunicação em diferentes contextos. O Tone Analyser realiza análise cognitiva linguística para identificar melhores entonações para diferentes contextos de comunicação. Ele detecta diferentes tipos de tons: emocionais (raiva, desgosto, medo, alegria e tristeza), propensão social (abertura, conhecimento) e estilos de escrita (analítica, confessional e argumentativa) em um texto. Não tem custo para até 2500 chamadas de API por mês.
Personality Insights
A ferramenta oferece insights baseados em dados transacionais e mídias sociais para identificar perfis psicológicos que podem determinar decisões de compra, intenções e comportamentos e, assim, ampliar taxas de conversão. É gratuito para até 1000 chamadas de API por mês.
Watson Assistant (formerly Conversation)
A ferramenta permite que desenvolvedores projetem formas para que aplicações interajam com usuários finais por meio de uma interface de conversação. O Dialog Service habilita aplicações com linguagem natural para prover respostas automáticas para questões encaminhadas por consumidores, encaminhamento de processos, ou atendimento para resolução de tarefas. A tecnologia pode, ainda, armazenar e mapear informações dos perfis dos usuários para aprender mais sobre os consumidores de uma empresa, guiando os consumidores por meio de processos ou os abastecendo de informações relevantes. A ferramenta é grátis para as primeiras 10 mil chamadas de APIs por mês.
O IBM Watson proporcionou uma quebra de paradigma para desenvolvedores e empresas de software, tornando acessível a experiência de trabalhar com computação cognitiva. Com as diversas APIs do Watson é possível agregar valor aos softwares desenvolvidos com essas tecnologias.
O mundo dos jogos atrai milhares de pessoas em todo o mundo, sejam eles eletrônicos, de tabuleiro ou por atividades físicas. Este texto tem por objetivo, esclarecer o conceito de gamification, mostrar casos de aplicação, e entender como utilizar este método no meio empresarial, para ampliar o engajamento efetivo em atividades variadas.
O que é Gamification?
Gamification (gamificação) pode ser definido, de forma mais consistente, como sendo uma estratégia, apoiada na aplicação de elementos de jogos, para atividades non-game que é utilizada para influenciar e causar mudanças no comportamento de indivíduos e grupos (BUNCHBALL INC., 2010). Gamificação é um termo recente, mas a ideia de utilizar os mecanismos dos jogos para resolver problemas e aumentar o engajamento, existe há bastante tempo.
Na educação infantil, os professores utilizam, de uma vasta variedade de jogos para desenvolver uma experiência lúdica, e mais interessante para os alunos, na hora de aprender os números, letras e sílabas.
No meio empresarial, temos diversos casos de aplicação da gamificação, seguem alguns exemplos:
Programa de Milhas
As companhias aéreas, têm dificuldade em fidelizar o cliente, pois este, acaba buscando outras companhias devido ao baixo custo da passagem. Por isso, as companhias criaram o programa de milhas, onde a cada viagem, são acumulados pontos que são revertidos em descontos, nas passagens aéreas e outros benefícios.
Duolingo
A plataforma de ensino de idiomas, soma quase 6 milhões de downloads do aplicativo na loja Google Play. Os conteúdos são divididos em níveis, e para desbloquear os níveis mais avançados, o usuário deve somar pontos, completando os exercícios disponibilizados. Um ranking de classificação é montado a partir da lista de amigos que utilizam a plataforma.
Strava
As corridas, pedaladas e outras atividades físicas, têm sido mais competitivas com o uso do Strava. Além do aplicativo armazenar as informações de geolocalização, e performance do usuário durante a atividade física, os trajetos comuns entre os atletas são monitorados. Com esta informação a plataforma monta um ranking diário, semanal, mensal e geral de performance dos atletas. O usuário conquista troféus, na modalidade bronze, prata e ouro, caso supere suas marcas pessoais, ou supere marcas de outros usuários.
Isto é engajamento!
Os desafios impostos pelos games geram uma motivação intrínseca, ou seja, parte da própria pessoa envolvida na atividade.
O termo “engajamento”, em um contexto empresarial, indica a conexão entre o consumidor e um produto ou serviço. Não há uma métrica específica, que mensure suficientemente o engajamento, é melhor pensar em um conjunto de métricas (ZICHERMANN; CUNNINGHAM, 2011), são elas:
Recência;
Frequência;
Duração;
Viralidade;
Avaliações.
Para um engajamento mais significativo, uma combinação entre as métricas deve ser levado em consideração, conforme a necessidade do negócio. Por exemplo, para o Duolingo, são consideradas mais importantes a frequência e duração da atividade no aplicativo.
E agora, como “Gamificar”?
Para a implementar a gamificação, alguns atributos chaves podem ser levados em consideração:
Programas de pontuação
Leaderboards / painel com ranking
Feedback / divulgação dos méritos alcançados
Regras
Premiações / recompensas
Selos, adesivos e distintivos
Mudança de nível
Troféus
É possível encontrar exemplos de gamificação em aplicativos de produtividade, mídias sociais, sites colaborativos, campanhas de incentivo, ações de marketing e muito mais, sempre com o objetivo de envolver os participantes, gerar mais engajamento e produtividade.
O método de gamificação se mostra muito eficiente, através dos desafios impostos e recompensas, que motivam e engajam os usuários. É importante conhecer o negócio, para analisar e descobrir qual forma de engajamento é necessária, e aplicar os métodos de gamificação baseados nesta perspectiva.
Autor: Gabriel Susin
Referências
BUNCHBALL INC. Gamification 101: an introduction to the use of game dynamics to influence behavior. 2010. Disponível em: <http://jndglobal.com/wp-content/uploads/2011/05/gamification1011.pdf>. Acesso em: 28 abril. 2018.
ZICHERMANN, G.; CUNNINGHAM, C. Gamification by design. Sebastopol: O’Reilly, 2011.
A extração de dados em tempo real é um processo realizado para captura dados de equipamentos de hardware com objetivo de empregar em aplicações de software especificas. Frequentemente utilizado em aplicações direcionadas a IoT (Internet das coisas) a extração de dados em tempo real tem algumas limitações, empregada de forma correta a extração pode se torna uma forte ferramenta para o desenvolvimento de diversas aplicações com foco em automação e controle.
A extração de dados em tempo real
O processo de extração de dados é utilizado com objetivo de reduzir o tempo e tornar mais assertivo o processo de monitoramento e utilização de dados. Por exemplo, um sistema que tem como objetivo realizar o controle de um processo industrial recebe com um frequência “x” uma informação referente ao processo que é inserida por um usuário passível de erro, essa informação gera um dado no sistema, se o mesmo sistema pudesse realizar a consulta da mesma informação no tempo em que ela foi gerada o sistema eliminaria o risco de erro durante esse pequeno processo, considerando que esse processo é realizado com frequência o tempo que usuário insere a informação reflete no tempo do monitoramento do dado, enquanto a coleta em tempo real diminui em grande parte esse tempo.
Como é realizada a coleta em tempo real
O sistema embarcado compatível com captura de dados em tempo real realiza a leitura dos sensores e se comunica com a aplicação, informando os dados capturados pelos sensores para utilização na aplicação.
Exemplos de utilização de captura de dados em tempo real.
Aplicativos de comunicação com computador de bordo do carro;
Centros de monitoramento de processos Industriais;
Identificação por radiofrequência RFID;
Sistemas de automação residencial;
Algumas vantagens na utilização de captura de dados em tempo real.
Elimina falhas humanas;
Agiliza e torna mais assertivo o processo;
Reduz os custos dos processos;
Aumenta a produtividade;
Autor: Tiago Spadetto dos Santos
Referências
KING ROGERS, Lorie. Data capture basics: Data capture technology can help an operation see its products in real time and take proactive steps to keep materials moving smoothly through the supply chain. Here’s a look at several basic data capture technologies.. 1. Disponível em: <https://www.mmh.com/images/site/MMH1110_EquipReport_Data.pdf>. Acesso em: 27 abr. 2018.
DO BRASIL, GE. Análise de dados e máquinas conectadas: conheça o centro de monitoramento da GE Water & Process Technologies! 1. Disponível em: <https://gereportsbrasil.com.br/análise-de-dados-e-máquinas-conectadas-conheça-o-centro-de-monitoramento-da-ge-water-process-6c4f79399132>. Acesso em: 20 abr. 2018.
A Representational State Transfer (REST), em português Transferência de Estado Representacional, é um estilo de arquitetura que define um conjunto de restrições e propriedades baseados em HTTP. Neste artigo, abordaremos alguns conceitos básicos sobre esta arquitetura:
O QUE É API?
O acrônimo API que provém do inglês Application Programming Interface (Em português, significa Interface de Programação de Aplicações), trata-se de um conjunto de rotinas e padrões estabelecidos e documentados por uma aplicação A, para que outras aplicações consigam utilizar as funcionalidades desta aplicação A, sem precisar conhecer detalhes da implementação do software.
Desta forma, entendemos que as APIs permitem uma interoperabilidade entre aplicações. Em outras palavras, a comunicação entre aplicações e entre os usuários.
O QUE É REST?
REST significa Representational State Transfer. Em português, Transferência de Estado Representacional. Trata-se de uma abstração da arquitetura da Web. Resumidamente, o REST consiste em princípios/regras que, quando seguidas, permitem a criação de um projeto com interfaces bem definidas. Desta forma, permitindo, por exemplo, que aplicações se comuniquem com clareza.
ORIGEM DO REST
O HTTP é o principal protocolo de comunicação para sistemas Web, existente há mais de 20 anos, e em todo esse tempo sofreu algumas atualizações. Nos anos 2000, um dos principais autores do protocolo HTTP, Roy Fielding, sugeriu, dentre outras coisas, o uso de novos métodos HTTP. Estes métodos visavam resolver problemas relacionados a semântica quando requisições HTTP eram feitas.
Estas sugestões permitiram o uso do HTTP de uma forma muito mais próxima da nossa realidade, dando sentido às requisições HTTP.
EM RESUMO
REST é abreviatura de Representational State Transfer;
É uma outra forma de desenvolver WebServices
REST é um conjunto de princípios que definem como Web Standards como HTTP devem ser usados
Aderindo aos princípios REST, teremos um sistema que explora a arquitetura da Web nosso beneficio
MÉTODOS HTTP
Abaixo, os métodos padrões para a execução de requisições HTTP, em consumo de serviços REST:
PUT (INSERIR)
Semelhante ao método POST, a ideia básica do método PUT é permitir a atualização de um recuso no servidor.
DELETE (EXCLUIR)
Como você já deve estar imaginando, o método DELETE é utilizado com o intuito de remover um recurso em um determinado servidor.
GET (CAPTURAR)
O método GET é utilizado quando existe a necessidade de se obter um recurso. Ao executar o método GET sob um recurso, uma representação será devolvida pelo servidor.
POST (ATUALIZAR)
Utilizamos o método POST quando desejamos criar algum recurso no servidor a partir de uma determinada representação. Exemplo disso é quando fazemos a submissão de algum formulário em uma página Web.
O QUE SIGNIFICA RESTFUL
Existe uma certa confusão quanto aos termos REST e RESTful. Entretanto, ambos representam os mesmo princípios. A diferença é apenas gramatical. Em outras palavras, sistemas que utilizam os princípios REST são chamados de RESTful.
REST: conjunto de princípios de arquitetura
RESTful: capacidade de determinado sistema aplicar os princípios de REST.
CONCLUSÃO
Neste artigo, eu procurei oferecer um rápida introdução sobre os conceitos por trás do REST, a arquitetura da Web. É extremamente importante entender o conceito da arquitetura Restful para evitar perda de tempo na construção da API, facilitando a vida de outros usuários que podem estar do outro lado do mundo tentando consumir a sua API. É muito importante evitar que suas APIS sofram alterações constantes e mudam de versão a todo momento, assim dificultando ainda mais a comunicação. Por isso é bom planejar e projetar bem antes de disponibilizá-la.