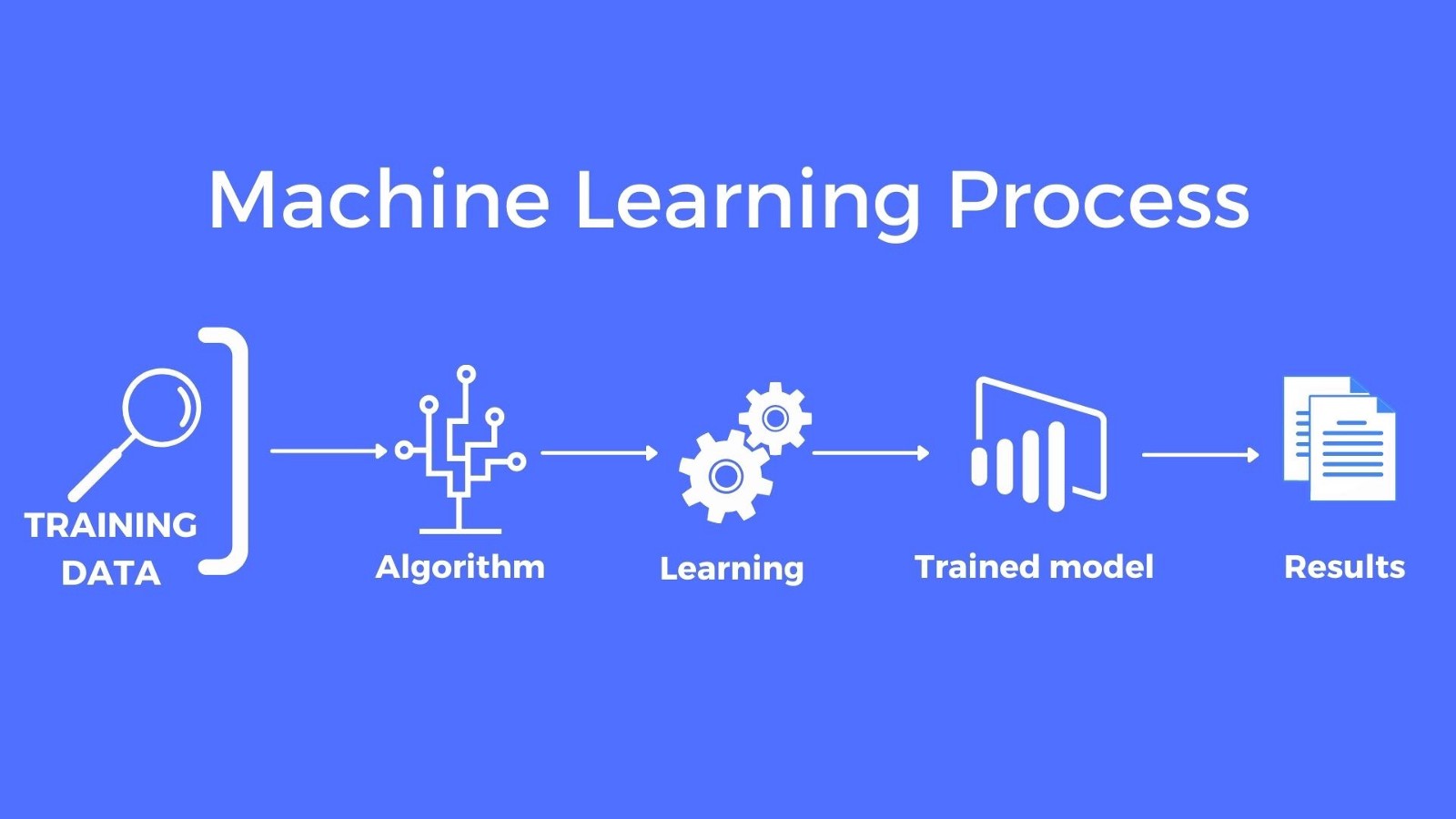
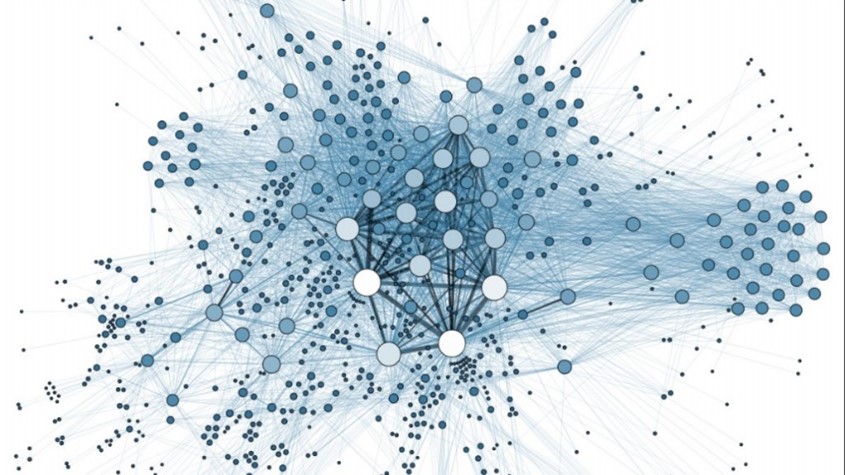
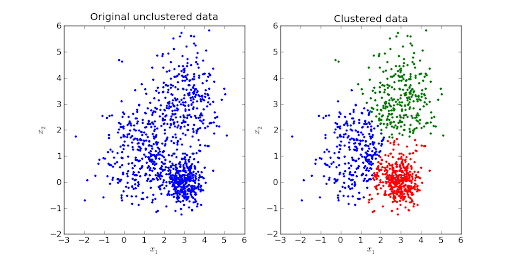
Cada vez mais democrática e acessível, não é novidade que a inteligência artificial tem ganhado espaço no dia a dia das pessoas, mas a utilização de ferramentas como essa não é recente. Há anos o comércio eletrônico tem usufruído da tecnologia para ser assertivo em suas recomendações e vendas. A ascensão do uso de dados de navegação é conhecida como BigData e é feito com a tecnologia de “cookies” e “tracking”, onde o algoritmo extrai informações da utilização em sites e aplicativos do usuário.
Uso da Inteligência Artificial para indicação de livros a leitores