AngularJS
No passado usavam-se sites estáticos, sem iteração com os usuários, porém logo surgiram aplicações Web, essas sim necessitavam de recursos e o nível de complexidade aumentou.
Inicialmente usou-se JavaScript/Jquery mas nem sempre ela garantia a alta produtividade e a facilidade na manutenção de código.
O que é o Angular JS?
AngularJS é um framework front-end que auxilia a criação de Single Page Aplications(SPA), e vem ganhando destaque desde de seu surgimento em 2011-2012 por Misko Every e Adam Ebrons, cujo objetivo era facilitar a criação de aplicações web. É baseado em um modelo MVW(Model View Whatever), uma brincadeira da Google dando um ponto final a uma longa discussão entre a comunidade de desenvolvedores que não chegavam em um acordo sobre o modelo utilizado cujos principais eram: MVC(Model View Controller), MVP(Model View Presenter) e MVVM(Model View View Model).
O começo:
Angular JS, foi desenvolvido por Misko Hevery em um projeto pessoal com o objetivo de aprimorar o desempenho de aplicações Web. Pouco tempo depois, Hevery entrou para o Google e aplicou sua framework no projeto Google feedback, diminuindo o número de linhas do código e aumentou sua performance. Google feedback e uma ferramenta que está presente em todos os produtos da Google como: Google+, Chrome, Hangouts entre outros, onde você pode enviar impressões do que estão acontecendo nos produtos como: erros, críticas e com isso o suporte vai poder observar se usuário final está gostando ou não dos produtos. Atualmente, o Google e o principal contribuinte para o código do AngularJs.
O AngularJS veio para padronizar a estrutura de desenvolvimento de aplicações para web, fornecendo um template com base nos padrões client-side.
Quem usa AngularJS:
Muitos clientes de grande porte usam Angular, devido a sua performance com simplicidade, os sites possuem o framework Angular: Airlines, paypal, cvs shop ,Micro Soft, Google Play,ABC News, San Disk, Trello.
Por que usar?
Usar este framework facilita a produtividade pelo reuso de código. Também visando a continuidade, hoje o mesmo está sendo mantido pelo Google, tendo como a certeza que ele não deixará o mercado tão cedo, tendo esforços de grandes equipes na linha de desenvolvimento, o angular segue muito bem o mantra da produtividade. Por ser orientado a componentes, é muito rápido e fácil programar com ele.
Praticamente qualquer coisa que se precisa já tem pronta por aí nos milhares de repositórios do GitHub. Existe inclusive um site que reúne mais de 2000 módulos open-source para facilitar a busca https://angular.io/guide/ngmodules. Possui comunidade Sólida o Repositório do Angular no GitHub tem 49 mil estrelas e mais de mil contribuintes, além de mais que 150 mil repositórios com scripts que utilizam a tecnologia.
No Stack Overflow, a maior comunidade de perguntas e respostas do mundo, temos quase 180 mil perguntas. Caso o interesse seja em vídeos sobre o assunto, o YouTube nos dá uma marca impressionante de 470 mil vídeos. O interesse da comunidade tem subido exponencialmente nos últimos anos, de acordo com o Google.
O Angular está sendo conhecido pela internet também pela sua curva de aprendizado. Em poucos minutos você aprende seus conceitos e já está desenvolvendo seu primeiro app.
O AngularJS usa em sua arquitetura o modo MVC (Model View Controller), que é um padrão para dividir uma aplicação em diferentes partes (modelo, visão e controle), cada uma com suas respectivas responsabilidades. Contando com três camadas de comunicação, que são elas:
- Controller : Sempre que você pensar em manipulação de dados, pense em model. Ele é responsável pela leitura e escrita de dados, e também de suas validações.
- View: Simples: a camada de interação com o usuário. Ela apenas faz a exibição dos dado.
- O responsável por receber todas as requisições do usuário. Seus métodos chamados actions são responsáveis por uma página, controlando qual model usar e qual view será mostrado ao usuário.
Um exemplo disso seria um restaurante, o Controller é o pessoal da cozinha que prepara o prato, mas não sabe para quem irá fazer, a View é o cliente que apenas recebe o prato e consome, mas não sabe quem fez, o Scope é como se fosse o garçom que faz o meio de campo entre Controller e View.
Outro recurso interessante para economia de dados e melhor performance é carregar apenas uma página principal, recursos de aplicação e outras páginas são carregadas por demanda, deixando a experiência mais fluida. Essa funcionalidade é conhecida como Route Engine. Este mecanismo de rotas é disponibilizado com o nome de angular-route.js.
A utilização deste framework torna a aplicação mais rápida e mais enxuta do que as outras formas de desenvolver interface para web.
Autor: Michel Toffolo
Fonte de referências:
https://tasafo.org/2014/11/26/porque-utilizar-angularjs-no-seu-proximo-projeto/
http://blog.algaworks.com/o-que-e-angularjs/






 O que é UI Design
O que é UI Design 





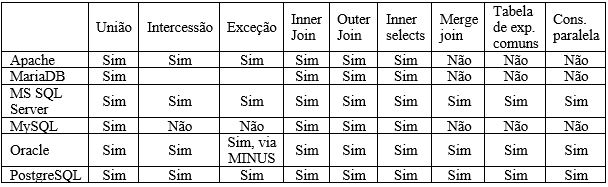
 Algumas definições importantes que devem ser apresentadas de um banco de dados relacional, como sua interface de comunicação o SQL, a sua integridade de dados, ou seja, a forma em que os bancos mantem sua precisão e consistência de dados, assegurada principalmente pelo seu sistema de transações que garantem que “tudo ou nada” seja gravado.
Algumas definições importantes que devem ser apresentadas de um banco de dados relacional, como sua interface de comunicação o SQL, a sua integridade de dados, ou seja, a forma em que os bancos mantem sua precisão e consistência de dados, assegurada principalmente pelo seu sistema de transações que garantem que “tudo ou nada” seja gravado.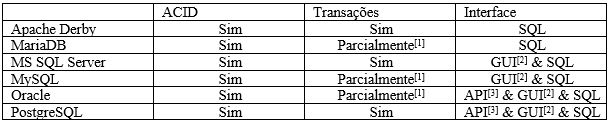
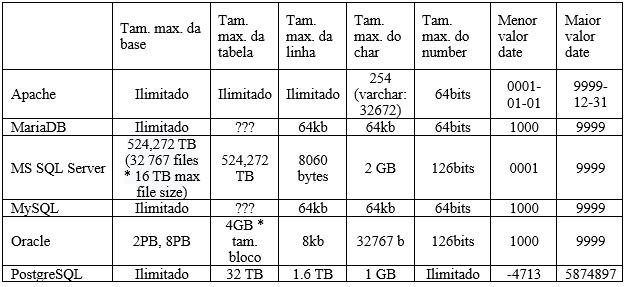

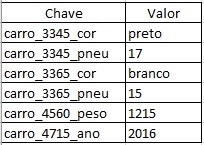
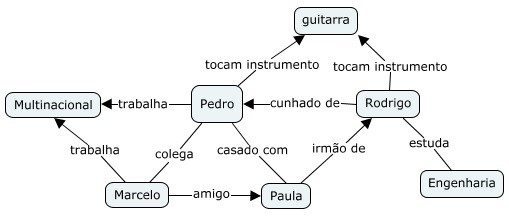
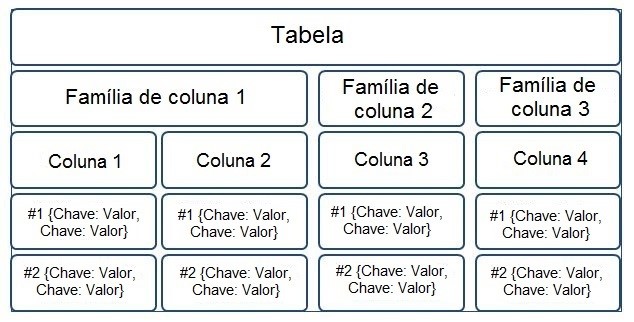
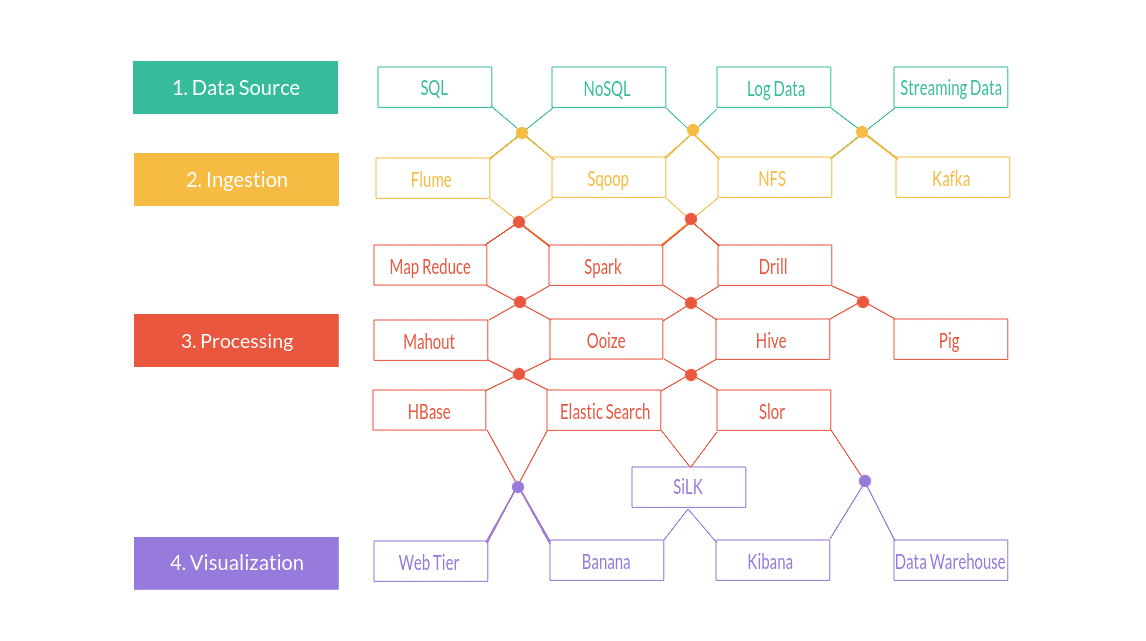
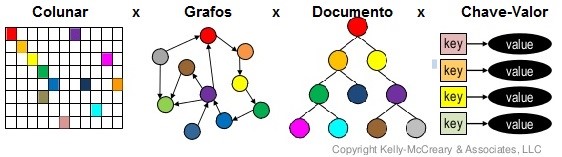 Os bancos de dados NoSQL não são todos iguais. Há grandes diferenças no que se refere como a forma de armazenamento e conceitos de modelagem. Basicamente se subdividem em técnicas de armazenamento diferentes. Há 4 tipos básicos de bancos de dados NoSQL, a seguir eles são descritos.
Os bancos de dados NoSQL não são todos iguais. Há grandes diferenças no que se refere como a forma de armazenamento e conceitos de modelagem. Basicamente se subdividem em técnicas de armazenamento diferentes. Há 4 tipos básicos de bancos de dados NoSQL, a seguir eles são descritos.