Desvendando AngularJS
No passado usavam-se sites estáticos, sem iteração com os usuários, porém logo surgiram aplicações Web, essas sim necessitavam de recursos e o nível de complexidade aumentou.

Feito por pessoas de TI para pessoas de TI

Desvendando AngularJS
No passado usavam-se sites estáticos, sem iteração com os usuários, porém logo surgiram aplicações Web, essas sim necessitavam de recursos e o nível de complexidade aumentou.

Criar um aplicativo de sucesso não é fácil. Além de fazer o aplicativo funcionar da forma desejada em vários tipos de dispositivos diferentes, o desenvolvedor deve pensar na infraestrutura, possíveis falhas, atualizações que não causem novos problemas, segurança nas transferências de dados, e tudo isso enquanto tenta alcançar o maior número de usuários possível e garantir uma experiência satisfatória para os mesmos. Pensando nisso, foi construído o Firebase, uma solução que possuí todas as ferramentas necessárias para a construção de um aplicativo de sucesso.


O Machine Learning é a ciência que faz com que os computadores exerçam suas funções sem que pareçam explicitamente programados para tal. O Machine Learning foi responsável pelo aprofundamento do desenvolvimento dos carros automáticos, recursos de reconhecimento de fala, buscas na web e possibilitou um avanço na compreensão do genoma humano. É um método de análise de dados que automatiza o desenvolvimento de modelos analíticos. Usando algoritmos que aprendem interativamente a partir de dados, o aprendizado de máquinas permite que os computadores encontrem respostas sem serem explicitamente programados para procurar algo específico.
É usado sempre que o programa é “treinado” sobre um conjunto de dados pré-definido. Baseado no treinamento com os dados pré-definidos, o programa pode tomar decisões precisas quando recebe novos dados. Exemplo: Por exemplo, uma peça de equipamento pode ter pontos de dados rotulados com “F” (com falha) ou “R” (em funcionamento). O algoritmo de aprendizagem recebe um conjunto de entradas junto com as saídas corretas correspondentes, e o algoritmo aprende comparando a saída real com as saídas corretas para encontrar erros. Em seguida, ele modifica o modelo de acordo. Por meio de métodos como a classificação, regressão e previsão o aprendizado supervisionado usa padrões para prever os valores do rótulo em dados adicionais não rotulados.
É usado contra a dados que não possuem rótulos históricos. O sistema não sabe a resposta certa. O algoritmo deve descobrir o que está sendo mostrado. O objetivo é explorar os dados e encontrar alguma estrutura neles. O aprendizado não supervisionado funciona bem em dados transacionais. Por exemplo, ele pode identificar segmentos de clientes com atributos semelhantes que podem ser tratados de modo semelhante em campanhas de marketing. Ou ele pode encontrar os principais atributos que separam os segmentos de clientes uns dos outros. As técnicas mais populares incluem decomposição de valores singulares, para segmentar tópicos de texto, recomendar itens e identificar os valores discrepantes dos dados.
É usado tanto contra dados rotulados quanto não marcados para o treinamento, normalmente uma pequena quantidade de dados rotulados com uma grande quantidade de dados não rotulados. Esse tipo de aprendizagem pode ser usado com métodos como a classificação, regressão e previsão. O aprendizado semisupervisionado é útil quando o custo associado à rotulagem é muito elevado para permitir um processo de treinamento totalmente rotulado. Os primeiros exemplos disso incluem a identificação do rosto de uma pessoa.
É muitas vezes usado para a robótica, jogos e navegação. Com o aprendizado por reforço, o algoritmo descobre pela tentativa e erro quais ações geram as maiores recompensas. Este tipo de aprendizagem tem três componentes principais: o agente (o aluno ou tomador de decisões), ambiente (tudo com o qual o agente interage) e ações (o que o agente pode fazer). O objetivo é que o agente escolha ações que maximizem a recompensa esperada ao longo de um determinado período de tempo. O agente atingirá o objetivo muito mais rápido seguindo uma boa política. Assim, o objetivo do aprendizado por reforço é aprender a melhor política.
É um algoritmo de apoio que utiliza um gráfico ou modelo de decisões e suas possíveis consequências, incluindo resultados de eventos futuros, custos de recursos e utilidade. Do ponto de vista da decisão de negócios, uma árvore de decisão é o número mínimo de perguntas que devem ser respondidas para avaliar a probabilidade de tomar uma decisão correta, na maioria das vezes. Como um método, permite-lhe abordar o problema de uma forma estruturada e sistemática para chegar a uma conclusão lógica.
São uma família de classificadores probabilísticos simples com base na aplicação Bayes ‘teorema com forte independência entre as características.
É um método para a realização de regressão linear. Você pode pensar em regressão linear como a tarefa de encaixar uma linha reta através de um conjunto de pontos. Existem várias estratégias possíveis para isso e a de “mínimos quadrados comuns” é assim: você pode desenhar uma linha e, em seguida, para cada um dos pontos de dados, medir a distância vertical entre o ponto e a linha e somá-los. A linha ajustada seria aquela em que esta soma de distâncias é a menor possível. Linear refere-se ao tipo de modelo que você está usando para ajustar os dados, enquanto mínimos quadrados refere-se ao tipo de métrica de erro que você está minimizando.
É uma poderosa forma estatística de modelar um resultado binomial com uma ou mais variáveis explicativas. Ela mede a relação entre a variável dependente categórica e uma ou mais variáveis independentes, estimando as probabilidades usando uma função logística, que é a distribuição logística cumulativa.
É um algoritmo binário da classificação. Dado um conjunto de pontos de 2 tipos em lugar N dimensional, o algoritmo gera um hiperplano (N – 1) dimensional para separar esses pontos em 2 grupos. Digamos que você tem alguns pontos de 2 tipos em um papel que são linearmente separáveis. O algoritmo encontrará uma linha reta que separa esses pontos em 2 tipos e situados o mais longe possível de todos esses pontos.
São algoritmos de aprendizagem que constroem um conjunto de classificadores e, em seguida, classificam novos pontos de dados, tendo um ponderado voto de suas previsões. O método de conjunto original é a média bayesiana, mas os algoritmos mais recentes incluem codificação de saída, correção de erros e reforço.
A tarefa de agrupar um conjunto de objetos de tal forma que os do mesmo grupo são mais semelhantes uns aos outros do que aqueles em outros grupos.
AUTOR: Ricardo José Boff
Novembro de 2017
https://www.sas.com/pt_br/insights/analytics/machine-learning.html
http://www.cienciaedados.com/conceitos-fundamentais-de-machine-learning/
https://br.udacity.com/course/intro-to-machine-learning–ud120
http://www.semantix.com.br/10-algoritmos-de-machine-learning/

“Integração Contínua é uma pratica de desenvolvimento de software onde os membros de um time integram seu trabalho frequentemente, …” Martin Fowler.
A Integração Contínua surgiu como parte das práticas da metodologia ágil XP (Extreme Programming), tendo como foco o desenvolvimento de software em ciclos menores, proporcionando melhor resposta a alterações e inclusão de novos requisitos. Mas a prática da Integração Contínua não se limita apenas a equipes utilizando a metodologia XP ou metodologias ágeis, trata-se de um conjunto de boas práticas que também podem ser adotadas em metodologias de desenvolvimento convencionais.
Devido ao grande impacto que vem ocorrendo com as metodologias ágeis, tais como eXtreme Programming, Scrum, entre outras, a integração contínua vem ganhando mais espaço e se tornando cada vez mais importante quando se fala em desenvolvimento de software.
A maior causa desse ganho de espaço da integração contínua ocorre pelo simples fato de que usando ela você tem um feedback instantâneo.
A grosso modo, a integração contínua funciona da seguinte forma: cada mudança que é feita no sistema, é feito o build automaticamente, todos os testes são feitos de forma automática e todas as falhas são detectadas nesse momento. Se alguma falha for detectada, toda a equipe fica sabendo, seja por email ou outras formas de comunicação.
Identificando os erros logo no início, a equipe pode tomar alguma ação para corrigi-los e assim não causar mais nenhum incomodo e/ou evitar que esses erros passe por eventuais testes e vão para as versões que posteriormente iriam para os cliente.
Claro que esses testes poderiam ser rodados manualmente, mas para isso teriam que ser usadas algumas horas de um integrante do projeto que poderia estar desenvolvendo, apenas para fazer essas validações.
Existem algumas ferramentas que podem ser utilizadas para fazer uso da integração continua:
• CruiseControl.rb: desenvolvida pela ThoughtWorks
• Selenium: desenvolvida pela ThoughtWorks
• Jenkios
• Hudson
Willian Marcolin

Os analistas de software se deparam com a modelagem de sistemas grandes e muito complexos, porem pensando no desenvolvimento e manutenção futura, necessitam de algo que os auxiliem a não tornar essas tarefas muito complicadas.
Nos últimos tempos, surgem sistemas cada vez mais complexos, com estruturas de classes imensas e arquiteturas de camadas muito divididas. Para evitar com que o software se torne tão complexo ao ponto de se perder o “controle”, houve-se a necessidade de quebrar um grande complexo em menores partes de menor complexidade, principalmente para um entendimento mais fácil de quem irá desenvolver e dar manutenção nessas aplicações. Além da quebra em subpartes, houve a necessidade dessas subpartes interagirem entre si, pelos mesmos motivos descritos a cima.
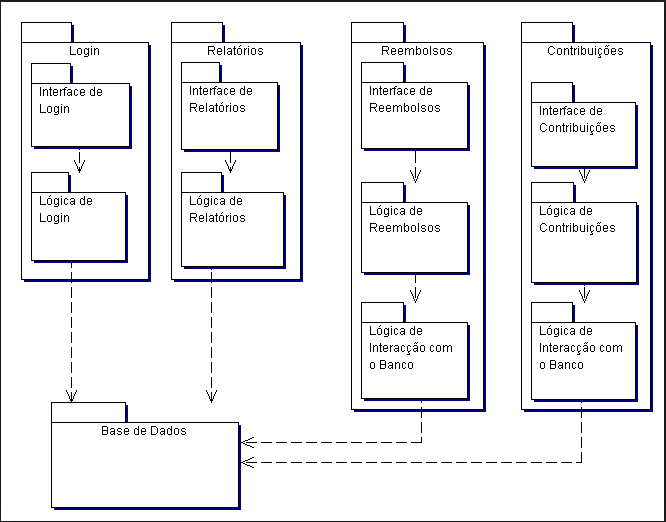
Com isso veio o conceito definido pela UML diagrama de pacotes ou também conhecidos como diagramas de módulos. Esses diagramas têm como conceito agrupadores lógicos de pedaços dos sistemas (nível superior) com dependência entre eles (interação de pacotes), ou seja, pacotes podem depender de outros pacotes. Esses elementos agrupados podem ser diagramas, classes, outros pacotes, entre outros. Os pacotes sempre têm um nome próprio e dentro alguns elementos que são agrupados conforme os tipos de elementos descritos a cima. Na realidade, não existem propriamente diagramas de pacotes em UML, em vez disso, pacotes e relações entre pacotes aparecem noutros diagramas, de acordo com o tipo de pacote:
Existem nos diagramas de pacotes 3 tipos de dependências:
Existem 3 tipos de visibilidades de elementos dentro dos pacotes:
Concluísse assim que diagramas de pacotes, são agrupadores genéricos de vários elementos vistos nos diagramas UML, tendo em vista deixar as aplicações com uma menor complexidade quebrando esses sistemas em subpartes menores, para uma fase de desenvolvimento mais tranquila, e para futuras manutenções se tornarem mais ágeis e “limpas”. Bem analisado e com o conceito de diagramas de pacotes bem maduro por quem for pensar, levantar os requisitos do sistemas e montar os diagramas possibilita as empresas terem softwares complexos e de fácil desenvolvimento e manutenção, permitindo uma agilidade na correção de bugs e realização de melhorias, aumentando o respeito do software no mercado e possibilitando o aumento de vendas e evitando ter aquele velho conhecido das empresas de softwares, que o código do “fulano” só ele sabe dar manutenção.
Pietro Zanandrea

Um banco de dados é uma aplicação que lhe permite armazenar e obter de volta dados com eficiência. O relacionamento se dá pela maneira como os dados são armazenados e organizados no banco de dados através de tabelas, com colunas e linhas. Estas tabelas são usadas para gravar os dados referentes ao objeto ou entidade relacionado. Onde cada linha representa os valores do objeto enquanto suas colunas definem tipos de dados a serem gravados que definem o objeto, ou seja, seus atributos.
 Algumas definições importantes que devem ser apresentadas de um banco de dados relacional, como sua interface de comunicação o SQL, a sua integridade de dados, ou seja, a forma em que os bancos mantem sua precisão e consistência de dados, assegurada principalmente pelo seu sistema de transações que garantem que “tudo ou nada” seja gravado.
Algumas definições importantes que devem ser apresentadas de um banco de dados relacional, como sua interface de comunicação o SQL, a sua integridade de dados, ou seja, a forma em que os bancos mantem sua precisão e consistência de dados, assegurada principalmente pelo seu sistema de transações que garantem que “tudo ou nada” seja gravado.
SQL
O SQL, ou Structured Query Language, tornou-se padrão do American Nacional Standards Institute (ANSI) em 1986, e este padrão de SQL é seguido por todos mecanismos populares de banco de dados relacionais, e alguns tem como padrão funções específicas referentes a ele, como adicionar, atualizar ou excluir linhas, ou mesmo recuperar dados para processamento de transação, além de analisar e gerenciar aspectos do banco.
Integridade de Dados
A integridade de dados se deve as várias constraints que ajudam nas regras de negócio evitando a gravação de campos importantes sem dados ou com dados errados, algumas dessas constraints são chaves primárias, chaves estrangeiras entre outras. Outra forma que os bancos têm para manter sua integridade é a transação, que deve ser completa como uma só e caso não aconteça nada é gravado e tudo volta como estava anteriormente.
As transações em bancos de dados devem estar em conformidade com o ACID, ou seja, atômicas, consistentes, isoladas e duráveis para que possam garantir a integridades dos dados no banco. A atomicidade prevê que toda transação deva ser executada com êxito, e no caso de falha seja invalidada. A consistência prevê que os dados gravados em banco por meio de uma transação devem aderir a todas regras definidas e suas restrições. O isolamento garante que cada transação seja independente por si só. A Durabilidade garante que toda alteração feita no banco seja permanente assim que a transação seja concluída com êxito.
Comparação
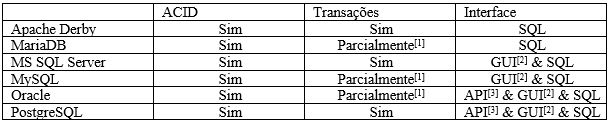
Tendo em vista o conteúdo abordado alguns bancos de dados serão comparados em alguns quesitos. Funcionalidades fundamentais que são implementadas nativamente em um SGBD, limites de tamanho de dados, recursos do banco de dados, são alguns dos dados que serão comparados.
As funcionalidades principais que contenham em cada banco comparado são: ACID, Transações e que tipo de interface é usada em cada um dos bancos.
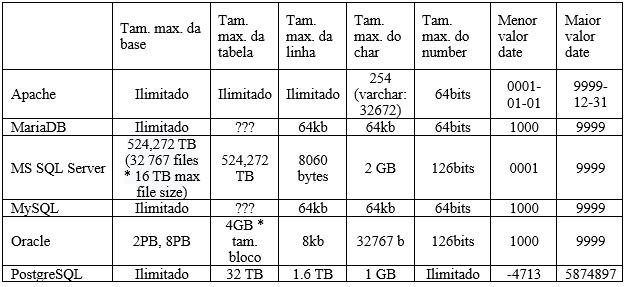
Informações sobre os limites de tamanhos de dados.
Alguns recursos utilizados pelos bancos de dados para consultas em suas tabelas.
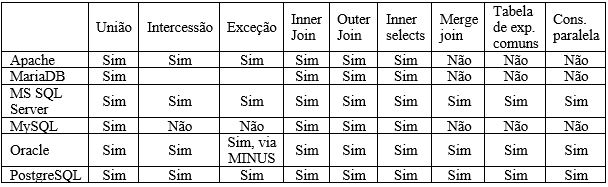
Pode-se perceber que com os dados comparados todos seguem um mesmo caminho, apenas algumas funcionalidades e recursos divergentes que dependendo da aplicação que irá utilizar pode gerar uma vantagem ou desvantagem.
Felipe Modesto
Links
https://elias.praciano.com/2013/09/o-que-e-um-banco-de-dados-relacional/
https://aws.amazon.com/pt/relational-database/
https://www.postgresql.org/docs/devel/static/explicit-locking.html
https://mariadb.com/kb/en/mariadb/mariadb-10122-release-notes/
https://dev.mysql.com/doc/relnotes/mysql/5.7/en/
http://www.oracle.com/technetwork/database/rdb/learnmore/rdb-pmatrix-rdb-086351.html
https://en.wikipedia.org/wiki/Comparison_of_relational_database_management_systems

“Gordon E. Moore, fez sua profecia, na qual o número de transistores dos chips teria um aumento de 100%, pelo mesmo custo, a cada período de 18 meses” (Wikipédia).
Isso significa que o poder de processamento dos chips praticamente dobraria até hoje. Não se sabe ao certo até quando essa lei ira prevalecer. Mas essa teoria esta presente na evolução do computador e principalmente em relação ao poder de processamento. Peças chaves do computador como processador e memória RAM são influenciadas diretamente (o HD que vem sendo substituído por discos de SSD que se mostram extremamente velozes). Em relação a custo e velocidade a memória RAM tem mostrado uma tendência a tornar-se mais vantajosa em relação a custo beneficio.

Normalmente as informações estão salvas em discos rígidos, que apresentam grande volume de espaços, porem com uma velocidade muito inferior a memória RAM e processador. Surge então, uma nova proposta tratando-se de SGDB, banco de dados em memória(IMDB). Tecnologia está que promete acelerar drasticamente o processo. Os fabricantes de SGDB já mostram-se adaptados a esse nova maneira, mais adiante veremos alguns dos mais conhecidos.
Trabalhar com mais informações e de forma mais rápida tende sempre a gerar melhores resultados. Velocidade e agilidade são primordiais, imaginem computadores analisando informações para a cura do câncer, ou big datas projetando ações futuras para as ações da empresa, não há tempo para perder ou esperar. Atualmente o volume de dados e informações pode ultrapassar terabytes e analisar estes grandes volumes de informações são fundamentais para a melhor tomada de decisão. Porém, isso pode tomar um tempo que não temos.
No entanto, você deve estar pensando “mas a memória RAM é volátil, não é muito arriscado perder dados?”. Se pensou assim, você está parcialmente certo, a RAM é volátil, ou seja, uma queda de luz, ou simples desligar da máquina poderiam levar seu banco para o espaço. Mas esse é o primeiro problema percebido e o primeiro a ser tratado. Os bancos de dados em memória irão sim utilizar o disco rígido ou memórias flash, para a persistência de dados. É como se um backup estive-se nessa memória permanente porém o processo e execução dos dados ocorre diretamente na RAM. Ai está o ganho de performasse sem correr o risco de perder informação. Dessa forma a utilização dos dados sempre presentes na memória otimiza a performance eliminando o tempo duplo gasto na transferência dos arquivos do banco de dados para o buffer e vice-versa.

Mesmo sendo uma tecnologia relativamente nova já existem muitas opções, pagas ou gratuitas. Aqui veremos algumas das mais conhecidas, SAP Hanna, Oracle Database in-Memory, MongoDB
Spa é uma empresa alemã que atualmente é uma das maiores referências em gestão empresarial. Através de excelentes frameworks que alinham seus processos eliminando a margem de erro.
Acesse qualquer dado a partir de qualquer dispositivo, transforme os dados em recursos inteligentes. Alta disponibilidade e segurança, com ferramentas de monitoramento e serviços locais ou em nuvem. Capaz de produzir insights valiosos em tempo real.
Recursos oferecidos pelo SAP HANNA são:
saiba mais em: https://www.sap.com/brazil/product/technology-platform/hana.html
Atuante em mais de 145 países. Especializada no desenvolvimento e comercialização de hardware e softwares e referencia mundial em banco de dados.
Saiba mais em: https://www.oracle.com/GOTO/IN-MEMORY
Fundada em 2007 por Dwight Merriman, Eliot Horowitz and Kevin Ryan. É uma tecnologia open source que traz consigo uma ideologia com os seguintes princípios:
MongoDB é uma excelente alternativas para banco de dados não relacionais. Seus pontos chaves são:
Veja como configurar o mongodb para trabalhar in-memory: https://docs.mongodb.com/manual/core/inmemory/
Como acompanhamos no início do artigo, fazer rápido é essencial. E fazer certo é fundamental, aqui acompanhamos ferramentas que de fato influenciam na velocidade e performance com que você pode trabalhar as informações no seu negócio. Analise sempre a situação, veja qual solução é ideal para sua empresa.
Conheça também outros modelos de banco de dados:
Banco de Dados não relacionais
Tags: Bando dados, imdb, mongodb, oracle, database in-memory, sap hanna
Referencias:
Oracle Database In-Memory – Youtube
A Comparative Study of Main Memory Databases and Disk-Resident Databases F. Raja, M.Rahgozar, N. Razavi, and M. Siadaty
https://www.sap.com/brazil/product/technology-platform/hana.html
https://www.oracle.com/GOTO/IN-MEMORY
https://docs.mongodb.com/manual/core/inmemory/
https://docs.oracle.com/cd/E18283_01/timesten.112/e14261/overview.htm
Autor: João Mello Corrêa
A arquitetura de softwares é importante no desenvolvimento de sistemas pois consiste nas definições dos componentes do software, propriedades externas e relacionamentos com outros softwares. Alguns dos mais conhecidos padrões de arquiteturas são o MVC (Model-View-Controller), MVP (Model-View-Presenter) e Pipeline.
Quando iniciamos um projeto temos que nos preocupar com a arquitetura da aplicação, nesta etapa é definida a plataforma a ser utilizada e como os componentes irão se organizar. Alguns padrões de arquitetura já foram criados com a finalidade de resolver os problemas mais corriqueiros de um projeto e em alguns casos são utilizadas combinações de padrões para atender melhor conforme as necessidades dos projetos.
O padrão de arquitetura Model View Controller (MVC) divide a aplicação ou um pedaço da sua interface em três partes distintas: modelo (Model), visão (View) e controlador (Controller). Ele foi desenvolvido inicialmente para mapear o método tradicional de entrada, processamento e saída, já utilizado por diversos programas.
A camada modelo contém as regras de negócio e os dados da aplicação, ele é o responsável por gerenciar um ou mais elementos, responder perguntas sobre o seu estado e quais as instruções necessárias para mudar seu mesmo. É o modelo que sabe o que o aplicativo deseja fazer e modela o problema a ser resolvido. A camada de visão tem a responsabilidade de apresentar as informações para o usuário, através de uma interface com gráficos, textos, imagens. A visão não tem conhecimento sobre o que a aplicação está fazendo, ela somente recebe instruções do modelo e do controlador e exibe-as na tela. Assim como a visão recebe as instruções das outras duas camadas, ela também envia o seu estado de volta para ambas.
O fluxo básico do padrão MVC começa com a interação do usuário com a interface e o controlador gerenciando este evento de entrada criado pelo usuário, ou seja, a interface é exibida pela camada de visão e controlada pelo controlador. O controlador irá acessar o modelo para realizar as alterações e atualizar os dados conforme a ação do usuário e após retorna as informações para a visão poder exibir para o usuário. Neste caso o modelo também não possui conhecimento direto da camada de visão, somente recebe requisições vindas pelo controlador e retorna informações ao controlador que irá repassar para a visão.
Alguns dos frameworks que possibilitam o desenvolvimento através da arquitetura MVC são ASP.NET MVC (.Net), Spring MVC (Java), Laravel (PHP) entre diversos outros.
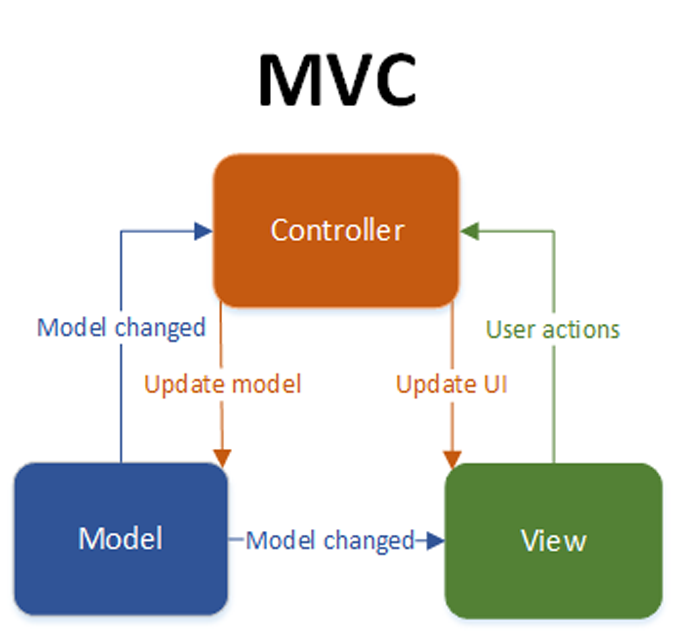 Figura 1: Objetos utilizados no MVC e suas interações.
Figura 1: Objetos utilizados no MVC e suas interações.
O padrão Model View Presenter (MVP) é uma variação do padrão MVC, com seu surgimento através da IBM e tem como objetivo principal separar a camada de apresentação das camadas de regras de negócio e dados, evitando que o modelo se comunique diretamente com a visão, sem passar pelo controlador. A camada presenter (apresentação) é similar a camada Controller do MVC, cuja função principal é ser mediadora entre as camadas. Ela atua sobre a camada de visão e a camada de modelo, recebendo dados do modelo, formatando-os e enviando para a visão exibir ao usuário. Em outras palavras a camada de apresentação é encarregada de atualizar a visão quando o modelo é alterado, e também de sincronizar o modelo em relação a visão.
Na camada de modelo estão os objetos a serem manipulados, este objeto implementa uma interface que irá expor os campos que a apresentação deverá atualizar quando sofrer alterações pela visão. Esta é a camada que se conecta com o banco de dados e tem a lógica necessária para processar os dados.
A camada de visão irá apresentar a interface com o usuário, possuindo as suas validações específicas de interface com o usuário. Esta camada processa os dados obtidos com o usuário e disponibiliza de forma adequada para as outras camadas. Um exemplo de camada MVP no C# é o Windows Forms.
O padrão MVP pode ser implementado de duas formas:
Passive View: A apresentação é a responsável pela ligação (binding) dos dados entre o modelo e a visão e vice-versa, com isso a visão se torna mais independente do modelo.
Supervising Presenter: A própria visão é responsável pela ligação (binding) dos dados do modelo.
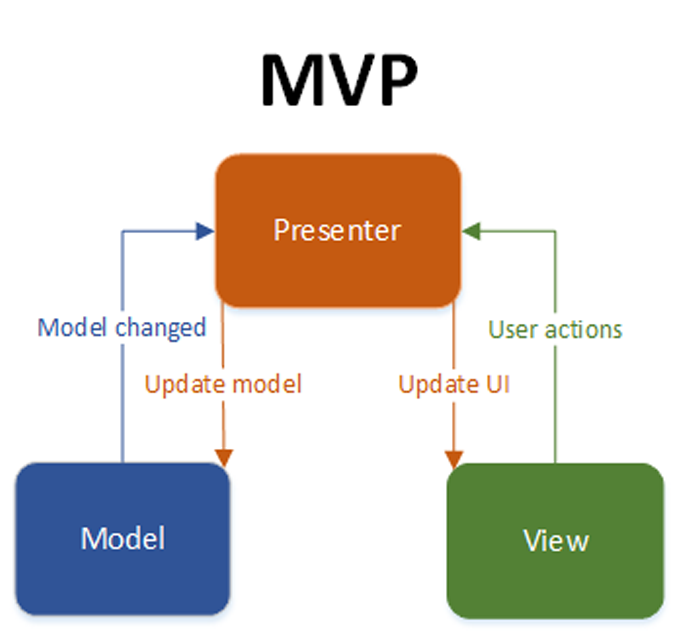
Figura 2: Objetos utilizados no MVP e suas interações.
O Pipeline, também conhecido como Pipe and Filter é uma estrutura para sistemas que processam cadeias de dados, estes processos são encapsulados em filtros e os dados são passados pelos canos (pipes) localizados entre os filtros. A saída de cada elemento de processamento é a entrada para o próximo elemento. O Pipeline é considerado como uma rede em que os dados fluem de uma origem até o destino através de pipes e os dados são manipulados e transformados quando são processados nos filtros.
Os pipes possibilitam o fluxo dos dados e os filtros são responsáveis pelo processamento desses dados, enviando para os pipes antes de todos os dados de entrada serem consumidos. Ele funciona de forma iterativa, onde o pipe se conecta a um filtro, porém não pode ser conectado a outro pipe e nem um filtro se conectar com outro filtro. A nível de arquitetura, o processamento é mapeado pelos filtros e os pipes são os condutores dos dados.
O uso de pipeline é indicado para dividir em uma sequência de pequenas tarefas uma tarefa de processamento maior. Algumas de suas vantagens são sua forma de encapsulamento, recombinação e reuso de dados, dando suporte a sua reutilização. Sistemas com arquitetura pipeline podem ser facilmente estendidos e modificados, tornando-se fácil a implementação em processadores paralelos ou multi-threads em processadores simples. Devido ao processamento ser em lotes, torna-se difícil criar aplicações interativas e pode haver exigência de um buffer de tamanho limitado para evitar sobrecargas na análise dos dados.
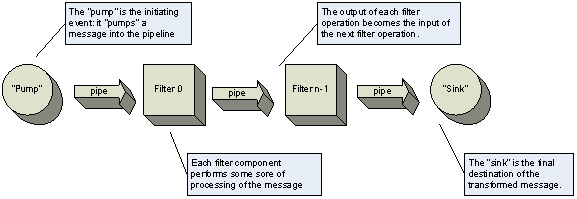
Figura 3: Sequência da arquitetura Pipeline
Nos dias atuais do desenvolvimento de sistemas percebemos a importância do uso de uma arquitetura adequada ao sistema, onde utilizando padrões de arquitetura é possível melhorar os atributos de qualidade de um sistema, sendo o mesmo determinante para o sucesso do sistema desenvolvido.
Autor: Thomas Milton Bellaver
Links Relacionados:
Introdução ao Padrão MVC. Disponível em: http://www.devmedia.com.br/introducao-ao-padrao-mvc/29308. Acessado em 25/04/2017.
Model-View-Presenter. Disponível em: https://pt.wikipedia.org/wiki/Model-view-presenter. Acessado em 25/04/2017
MVP: Model View Presenter – Revista .net Magazine 100. Disponível em: http://www.devmedia.com.br/mvp-model-view-presenter-revista-net-magazine-100/26318 Acessado em 25/04/2017
Pipes e filtros. Disponível em: https://pt.wikipedia.org/wiki/Pipes_e_filtros. Acessado em 25/04/2017
Padrões Arquiteturais de Sistemas. Disponível em: https://pt.slideshare.net/santanavagner/padroes-arquiteturais-de-sistemas. Acessado em 25/04/2017
 Novas aplicações web e sites com diferentes finalidades são criados a todo instante nos dias atuais, diversas ferramentas que antes eram hospedadas em servidores locais estão deixando este ambiente de lado e migrando para soluções web ou em nuvem devido à redução de custos. A questão é: Como e onde hospeda-los? Para isso existem empresas que disponibilizam recursos, espaço em seus servidores ou data centers e conexão à internet, oferecendo um serviço dedicado que propõe segurança dos dados e alta disponibilidade.
Novas aplicações web e sites com diferentes finalidades são criados a todo instante nos dias atuais, diversas ferramentas que antes eram hospedadas em servidores locais estão deixando este ambiente de lado e migrando para soluções web ou em nuvem devido à redução de custos. A questão é: Como e onde hospeda-los? Para isso existem empresas que disponibilizam recursos, espaço em seus servidores ou data centers e conexão à internet, oferecendo um serviço dedicado que propõe segurança dos dados e alta disponibilidade.
Lista de hostings para hospedagem de sites e aplicações web
Ao buscar um serviço de hosting para hospedagem de um site, devemos considerar alguns pontos relevantes quanto aos serviços oferecidos por empresas, dentre eles estão: espaço de armazenamento em disco, taxa de transferência, domínios, compatibilidade com sistemas operacionais, suporte ao cliente e preços.
A seguir será apresentado uma lista dos 10 serviços de hostings para hospedagem de sites, expondo informações como espaço disponível, limite de transferência, domínios, compatibilidade, preços e outras informações consideradas importantes:
HostGator: Oferece domínio único, 100GB de armazenamento, transferência ilimitada, contas de e-mail grátis e criador de sites, seu preço é de R$12,79/mês ou R$153,50/ano. Possui descontos na renovação, além de suporte ao usuário 24/7.
GoDaddy: Oferece um plano de R$23,99/mês com 100GB de armazenamento, transferência ilimitada, 1 conta de e-mail com 10GB de armazenamento e 1° ano de domínio grátis. Suporte ao usuário funciona de segunda a sexta via telefone.
UOL Host: Uol oferece em seu plano de hosting, um armazenamento de 10GB, transferência ilimitada, até 30 contas de e-mail com 12GB de armazenamento cada, 2 domínios e um construtor de sites por um valor de R$9,90/mês. O suporte ao usuário funciona 24/7 por e-mail, telefone e chat.
Locaweb: Armazenamento ilimitado, transferência ilimitada, 25 contas de e-mail com 10GB cada e criador de sites por R$17,90/mês no 1° ano depois passa a ser R$30,90/mês nos anos seguintes. Suporte ao usuário 24/7 via telefone e chat e oferece um 1 ano de domínio grátis.
DreamHost: Armazenamento ilimitado, transferência ilimitada, contas de e-mail ilimitadas com 2GB de armazenamento cada e 1 domínio por R$18,19/mês. Oferece suporte ao usuário 24/7 em inglês.
Kinghost: Armazenamento de 10GB, transferência ilimitada, contas de e-mail ilimitadas com um tamanho total de 50GB, criador de sites e serviço de proteção SSL por um valor de R$12,50/mês. Oferece bancos de dados em SSD e backup diário incluso nos planos. Suporte ao usuário funciona 24/7 através de chat, telefone e e-mail.
Bluehost: Armazenamento de 50GB, transferência ilimitada, até 5 contas de e-mail com até 100MB de armazenamento cada, criador de sites e 1 domínio por R$12,50/mês. Oferece suporte ao usuário 24/7 em inglês e CloudFlare pronto para utilização.
Inmotion hosting: Armazenamento ilimitado, transferência ilimitada, contas de e-mail ilimitadas com armazenamento ilimitado, 2 domínios, criador de sites e compatibilidade com diversas linguagens de programação por R$18,92/mês. A empresa oferece armazenamento em disco SSD e backup gratuito, além de um atendimento ao usuário que funciona 24/7 em inglês.
Digital Ocean: Armazenamento de 20GB SSD, 1TB de transferência, contas de e-mail conforme solicitado pelo contratante com acréscimo no valor padrão. O valor mínimo dos planos é de R$15,00/mês, mas a empresa permite que o contratante possa aumentar o armazenamento em disco por aproximadamente R$30,00 cada 100GB de armazenamento SSD. O serviço é oferecido através de servidores virtuais (VPS). O serviço de suporte oferecido é em inglês através de tickets.
Media Temple: Armazenamento de 20GB SSD, 1TB de transferência, até 1000 contas de e-mail, permite até 100 sites e compatibilidade com diversos bancos de dados por um valor de R$63,00/mês. Suporte ao usuário oferecido funciona 24/7 através de e-mail, chat, telefone e twitter, apenas em inglês. Também está incluso backup diário automático.
Há uma infinidade de serviços disponíveis por empresas, cada um deles com especificações e ofertas diferentes que podem atender diversos tipos de aplicações. Para isso é necessário que usuário saiba avaliar a necessidade de recursos que sua aplicação ou site irá precisar. Nesta lista foram apresentados os planos mais simples disponíveis pelas empresas selecionadas, porém cada uma das empresas citas oferecem planos mais robustos oferecendo uma maior quantidade de recursos.
Autor: Adriano Saldanha de Oliveira
Links relacionados:
https://tudosobrehospedagemdesites.com.br/ranking-melhor-hospedagem-de-sites/
https://tudosobrehospedagemdesites.com.br/hospedagem-de-sites/
Como os idiomas reais, cada linguagem de programação tem suas respectivas regras, pontuações, pausas e pontos, sendo necessário conhecer esses padrões para manter o código organizado e com fácil entendimento. Nas linguagens de programação precisamos seguir alguns padrões básicos para que o código não vire uma bagunça no meio de um desenvolvimento.
Java é umas das linguagens mais utilizadas hoje no mundo do desenvolvimento e os programadores costumam utilizar alguns padrões definidos pela comunidade que serão descritos abaixo.
Mantenha o tamanho dos nomes grande o bastante para transmitir o que eles representam. Exemplo: primeiroNome, sobrenome, ordemServico.
Os nomes de classe devem ser substantivos e, em caso de nomes compostos, utilize nomes com a primeira letra de cada palavra interna maiúscula. Use palavras inteiras evitando acrônimos e abreviaturas. Exemplo: Cliente ou ContaCliente.
Os nomes dos métodos devem ser verbos, em casos compostos com o primeiro nome minúsculo, e com a primeira letra de cada palavra interna em maiúsculo. Exemplo: calcularPagamento().
Os nomes de variáveis devem estar com uma primeira letra minúscula e, em caso de nomes compostos, com a primeira letra de cada palavra interna em maiúsculo. Exemplo: contraPeso, primeiroNome.
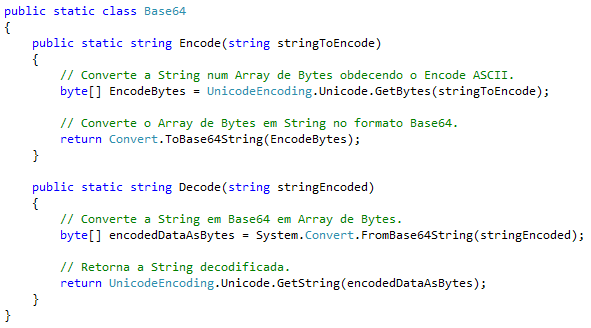
Os nomes de constantes para tipos de dados ordinais devem ter todas as letras em maiúsculo, separadas por underline. Exemplo:
| 1
2 |
public static final int MAX_POLICY_AMOUNT; ou
public static final char PROCESS_INFO_COMMAND; |
Adicione comentários para facilitar a compreensão do código. Mantenha o comentário simples e separe-os de tal forma o código fique limpo e legível. Escreva também os comentários onde alguma explanação é necessária. Não escreva comentários para as coisas óbvias.
Forneça linhas em branco entre as seções do código para melhorar a legibilidade. Use uma linha em branco nas seguintes circunstâncias:
Use o espaço em branco para melhorar a legibilidade do código nas seguintes circunstâncias: Entre uma palavra-chave e um parêntese. Exemplo:
| 1
2 |
while (condicao) {
} |
Após vírgulas na lista entre parênteses. Exemplo:
| 1 | operacao(param1, param2, param3); |
Entre um operador binário e seu operando. Exemplos:
| 1
2 |
x += y + z;
a = (a + b) / (c * d); |
Declare uma variável local por linha do código e adicione um comentário que identifique a variável. Exemplo:
| 1 | int contador = 0; // contador para número de referências |
Para declarar atributos utilize os seguintes padrões:
Para declarar métodos de membro utilize os seguintes padrões:
Cada linha deve conter no máximo um comando.
Siga um esquema consistente para a abertura e fechamento de chaves. Alinhe a abertura e fechamento das chaves verticalmente. Isto facilitará a identificação do começo e término dos blocos. Exemplo:
| 1
2 3 4 5 6 7 8 9 |
class Cliente
{ public void operacaoParaCliente() { if(condicao) { } } } |
Sempre utilize chaves para delimitar blocos de comandos, mesmo que estes tenham apenas uma instrução:
| 1
2 3 4 5 6 |
if(determinadaCondicao) // EVITE ISSO!
realizaOperacao();
if(determinadaCondicao){ // OK realizaOperacao(); } |
Quando utilizamos padrões e boas práticas, garantimos que todos da equipe conseguirão ter o mínimo de entendimento do código que está sendo desenvolvido. Em linguagens como o Java já temos padrões indicados e definidos pela comunidade de forma documentada para que os desenvolvedores adotem um padrão universal de codificação, facilitando assim o entendimento de qualquer código desenvolvido na linguagem. Visto isso é indicado adotar sempre o padrão de codificação da linguagem utilizada.
Padrões de Codificação, por Tadeu Pereira, acesso em: <http://www.devmedia.com.br/padroes-de-codificacao/16529>
Introdução a Padrões de Codificação, por Diego Eis, acesso em: <https://tableless.com.br/introducao-a-padroes-de-codificacao/>
Dicas de Boas Práticas de Codificação, por Luiz Gustavo S. de Souza, acesso em: <https://luizgustavoss.wordpress.com/2010/09/09/dicas-de-boas-praticas-de-codificacao/>
Convenções de Código Java, por Carlos Eduardo, acesso em: <http://www.devmedia.com.br/convencoes-de-codigo-java/23871>

Banco de dados não relacionais ou distribuídos, tem como princípio básico não possuírem o conceito de modelagem por tabelas como o relacional, diferenciam-se pela sua utilização horizontal, através da distribuição de dados em diferentes servidores. São indicados para aplicações projetadas com alta carga de dados, onde o modelo relacional não consegue atender. Para a maioria das aplicações de grande escala, a disponibilidade e a tolerância são mais importantes que a consistência, sendo as características BASE mais fáceis de serem alcançadas do que as ACID. Um caso importante a ser citado foi o Banco NoSQL CassandraDB, que inicialmente foi desenvolvido para um recurso do Facebook.
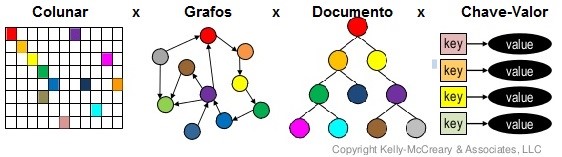 Os bancos de dados NoSQL não são todos iguais. Há grandes diferenças no que se refere como a forma de armazenamento e conceitos de modelagem. Basicamente se subdividem em técnicas de armazenamento diferentes. Há 4 tipos básicos de bancos de dados NoSQL, a seguir eles são descritos.
Os bancos de dados NoSQL não são todos iguais. Há grandes diferenças no que se refere como a forma de armazenamento e conceitos de modelagem. Basicamente se subdividem em técnicas de armazenamento diferentes. Há 4 tipos básicos de bancos de dados NoSQL, a seguir eles são descritos.
NoSQL orientado a documento: consiste em uma estrutura baseada em uma coleção de documentos, sendo um documento um objeto que contém um código único com um conjunto de informações, podendo ser strings, documentos aninhados ou ainda listas. Inicialmente pode ser semelhante ao modelo de chave-valor(Key-value), no entanto, diferencia-se m ter um conjunto de documentos e cada um destes recebe um identificador único, assim como as chaves, dentro da coleção. Ao se armazenar os dados em JSON, o desenvolvimento é facilitado, pois há suporte a vários tipos de dados. Exemplos destes são o MongoDB e CouchBase.

Figura 1 – organização de um NoSQL orientado a documento.
NoSQL Key-Value (chave-valor): consiste em uma modelagem que indexa os dados a uma chave. Ao se armazenar os dados, sua forma de procura se dá por uma base similar a um dicionário, onde estes possuem uma chave. Esta forma de armazenamento é livre de “schema”, permite a inserção de dados em tempo de execução, sem conflitar o banco e não influenciando na disponibilidade, pois seus valores são isolados e independentes entre si. Alguns exemplos são: Oracle NoSQL, Riak, Azure Table Storage, BerkeleyDB e Redis.
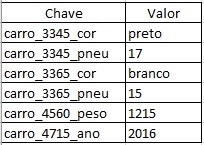
Figura 2 – Exemplo de organização de um banco de dados NoSQL chave-valor.
NoSQL representado por Grafos: Este modelo armazenamento utiliza três componentes básicos: um grafo para representar um dado, arrestas ou ligações para representar a associação entre os grafos e os atributos (ou propriedades) dos nós e relacionamentos. Modelo altamente usado onde exijam dados fortemente ligados. Este modelo é vantajoso onde há consultas complexas frente aos outros modelos, pois seu diferencial é o ganho de performance. Alguns exemplos são: Neo4J, OrientedDB, GraphBase e InfiniteGraph.
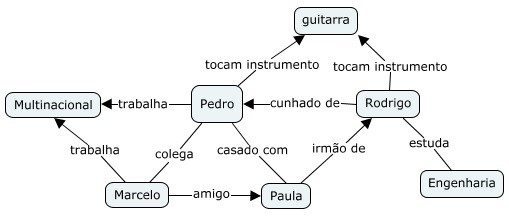
Figura 3 – Exemplo de organização de um banco de dados NoSQL orientado a grafos.
NoSQL modelo Colunar: Este modelo foi inicialmente desenvolvido baseado no Big Table da Google. Basicamente consiste em uma Tabela, onde nela possui várias famílias de colunas, e dentro destas famílias, colunas onde estão as propriedades. Neste modelo, as entidades são representadas por tabelas e os dados gravados em disco modelo caracteriza-se por indexar um dado por uma Tripla, que consiste em linha, coluna e timestramp, sendo este o que permite verificar as diferentes versões de um dado. Os valores das propriedades das colunas podem são semelhantes ao modelo “Key-Value”. São bancos de dados indicados para mídias sociais e problemas que envolvem consultas complexas.
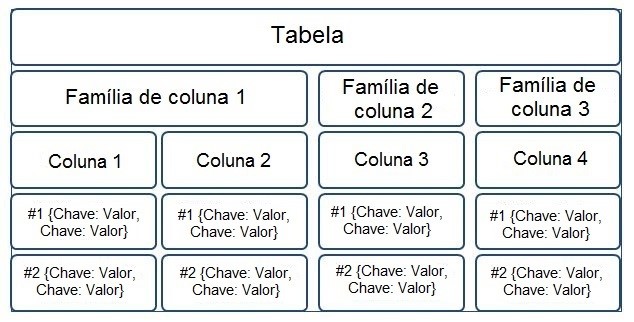
Figura 4 – Exemplo de organização de um banco de dados NoSQL orientado a Colunas.
Há também o Hadoop, que é um framework paralelo no processamento de dados que tem sido usado para redução de mapas e Jobs. Diferentemente do Spark que armazena os dados em memória, o Hadoop armazena em disco e utiliza a técnica de replicação para garantir tolerância a falhas. Foi projetado para funcionar desde um único servidor até um cluster com milhares de máquinas. È uma solução comcebida para detectar e tartar falhas na camada de aplicação, fornecendo um serviço de alta disponibilidade baseado em um grid de computadores. No entanto o Hadoop possui uma grande latência para as consultas. Há dois componentes principais do Hadoop: Hadoop Distributed File System (HDFS) e o Mapreduce.
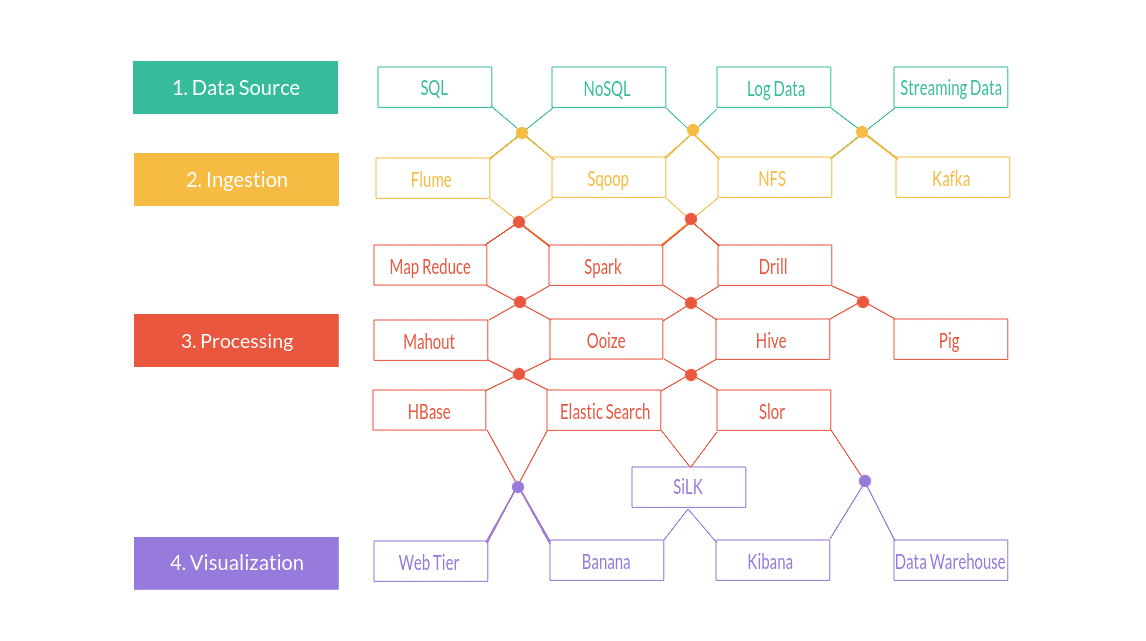
Figura 5 – Exemplo de funcionamento do Hadoop.
Referências Bibliográficas.
https://pt.slideshare.net/Celio12/trabalho-no-sql-aricelio-de-souza – acessado 17/04/2017
Nosql Essencial – Um Guia Conciso Para o Mundo Emergente da Persistência Poliglota – Martin Fowler, Pramod J. Sadalage – ISBN: 978-85-7522-338-3 – Ano: 2013
https://dzone.com/articles/a-primer-on-open-source-nosql-databases – acessado 17/04/2017
http://aptuz.com/blog/is-apache-spark-going-to-replace-hadoop/ – acessado em 13/05/2017
https://www.ibm.com/developerworks/br/data/library/techarticle/dm-1209hadoopbigdata/ acessado em 12/05/2017
O diagrama de implantação é o diagrama estrutural responsável por estabelecer a relação entre os recursos de infraestrutura e artefatos do sistema, em outras palavras, ele mapeia arquitetura do hardware às necessidades do software a ser implantado. Esse diagrama é basicamente implementado com “nós”, “associações entre nós”.
Os “nós” são formas ou containers de UML, usadas para representar um item de hardware, como um servidor físico, seja ele de armazenamento ou execução da aplicação ou de módulos isolados, ou ainda um “nó” pode significar o ambiente de execução do software ou parte dele. “Nós” também podem conter outros nós, de maneira que demostrem a real estrutura do sistema, por exemplo, um nó pode conter os arquivos necessários, encapsulados por um “nó” que representa o servidor de armazenamento, este por sua vez, também encapsulado por outro “nó” que representa o ambiente de execução e ainda se necessário, encapsulado em outro “nó’ com outros ambientes de execução.
As associações entre os “nós” representam as relações destes itens no mundo real, bem como a forma que interagem e trocam informações. São representados por retas complementadas por um rótulo que descreve da relação entre eles ou a maneira como integarem entre si, sendo esse rótulo um mecanismo da UML conhecido como esteriótipo.
“A UML tem muitos tipos diferentes de setas tracejadas que parecem idênticas. Felizmente, a UML permite que você marque um elemento de modelo para indicar exatamente que tipo de elemento ele é. UML chama esse rótulo de um estereótipo. Você mostra o estereótipo ao lado do elemento (precedendo o nome do elemento, se houver). UML tem vários estereótipos predefinidos ou você pode definir o seu próprio para indicar um tipo especial de elemento para seus próprios fins”. (Chonoles & Schardt, 2003)
O propósito deste modelo de diagrama é documentar os itens envolvidos a fim de tornar ágil o processo de implantação de software. A Figura 1 apresenta um exemplo deste diagrama.
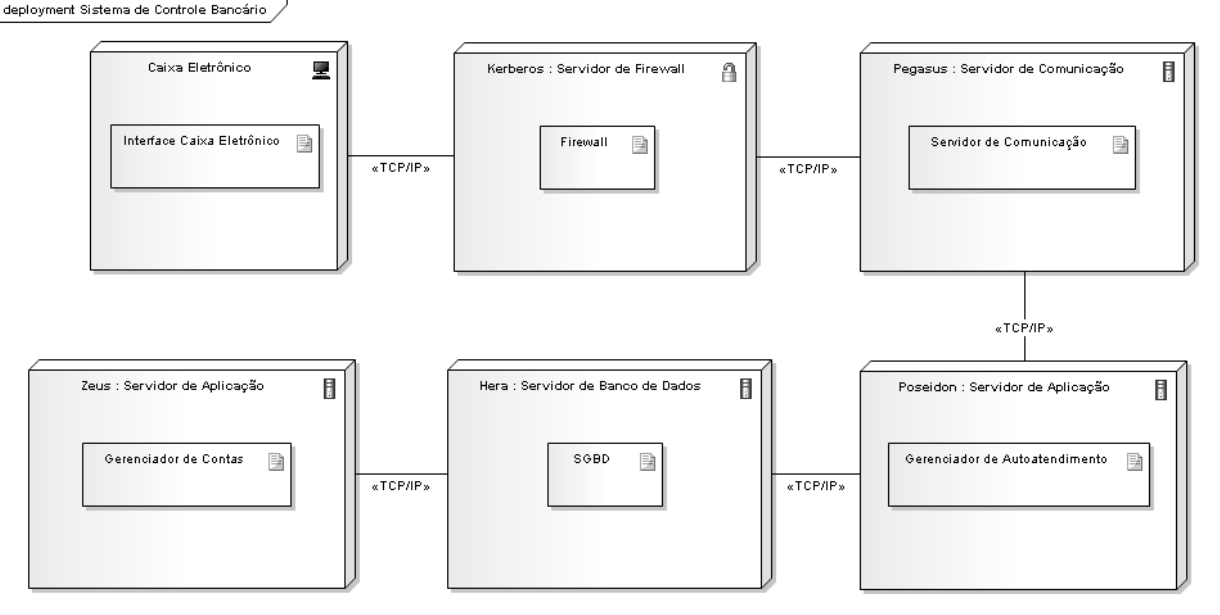
O diagrama de implantação é um forte aliado para descrição de sistemas complexos e distribuídos onde os hardwares envolvidos tem um papel crucial na execução da aplicação. Claro que todos os softwares são codependentes do hardware, porém em alguns casos o hardware se torna o recurso mais prioritário. Por exemplo, em um software na nuvem onde queremos fazer backups diários usando a infraestrutura da empresa Amazon, é extremamente importante que se determine e explicite todos os recursos a serem utilizados no diagrama, bem como o número de servidores a serem comunicados, interligados pelos estereótipos dos meios ou protocolos de comunicação, a segurança da aplicação, etc.
Pedro Oziel Escobar da Silva
Chonoles, M. J., & Schardt, J. A. (2003). UML 2 for Dummies. Hungry Minds.
Guedes, G. T. (2007). UML UMA ABORDAGEM PRÁTICA. Novatec.
O Diagrama de Componentes apresenta uma visão estática de como o sistema será implementado e quais os componentes utilizados. Através deste diagrama, são identificados os arquivos que irão compor o software em termos de módulos, bibliotecas, formulários, etc., além de identificar os relacionamentos destes. Além de modelar os componentes, este diagrama destaca a função de cada componente, facilitando a sua reutilização em outros sistemas.
É utilizado para:
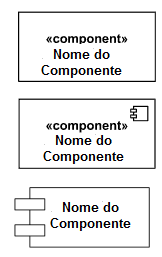
Componente
Um componente é um nome genérico dado à menor parte a ser considerada na modelagem do sistema (uma classe, uma função, uma parte de um hardware, etc.). Os símbolos de componentes podem ser:
Um componente pode apresentar um estereótipo, i.e., uma definição do que este componente é. Os principais estereótipos são:
Interface fornecida
Designa uma interface que o próprio componente possui e oferece para outros componentes. Isto significa que o componente só pode ser acessado pela interface fornecida.
Esta interface possui a forma de um pirulito:
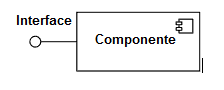
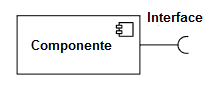
Interface requerida
Designa uma interface necessária para que o componente se comunique com outros componentes. Esta interface será conectada, então, em uma interface fornecida de outro sistema.
Classes e componentes internos
Um componente pode possuir classes e componentes internos. Chamamos de visão caixa preta quando um ou mais componentes não apresentam seus elementos internos, enquanto caixa branca é o nome dado quando os componentes apresentam seus elementos internos.
Portas
Porta são elementos que permitem que elementos internos possam se comunicar com elementos externos do componente.
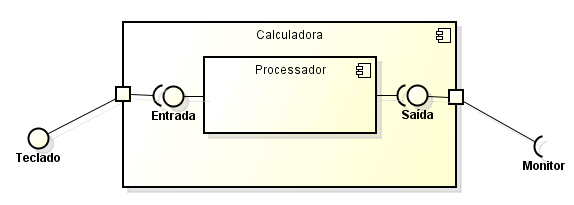
REVISTABW. UML: Diagrama de Componentes. Revista Brasileira de Web: Tecnologia. Disponível em http://www.revistabw.com.br/revistabw/uml-diagrama-de-componentes/. Criado em: 26/12/2013. Última atualização: 24/07/2015. Visitado em: 27/04/2017
Paulo Ricco Sirtoli
O diagrama de objetos permite uma visão de um conjunto de instancias existentes em determinado momento de execução do programa, ou seja, o diagrama de objetos é uma “fotografia” das instancias das classes.
Afinal, diagrama de objetos é a mesma coisa que diagrama de classes?
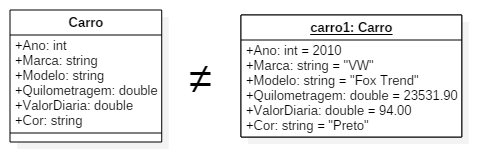
O diagrama de objetos não é uma representação do diagrama de classes mas sim uma variação dele.
O diagrama de objetos utiliza uma notação semelhante a usada nos diagramas de classes, entretanto, enquanto o diagrama de classes representa a estrutura de relações de classes que servem de modelo para objetos, os diagramas de objetos mostram instancias e links entre estas instancias.
Abaixo vemos um diagrama de classes simplificado para um sistema de locadora de veículos.
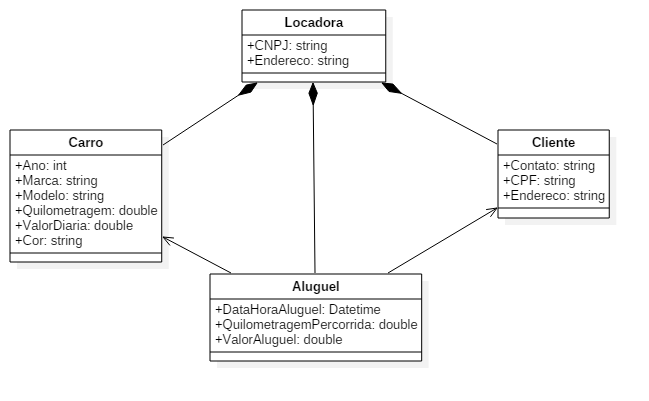
A seguir vemos um diagrama de objetos criado a partir do diagrama de classes acima. Este diagrama consiste em um cliente (clienteAtual) que em uma locadora (locadoraAtual) realizou dois alugueis (aluguel1, aluguel2) de dois carros (carro1, carro2).
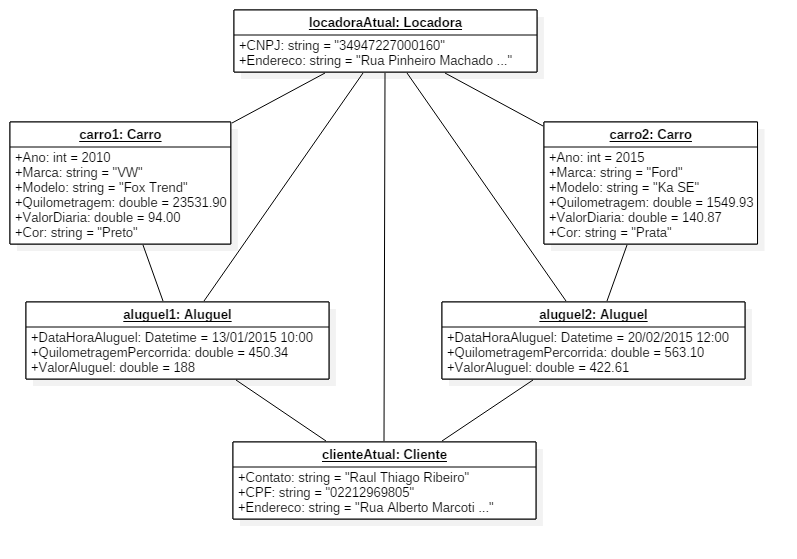
Dicas
Os diagramas de objetos não são tão importantes como os diagramas de classes, porem eles são complementares de modo a exemplificar diagramas complexos ajudando na compreensão do sistema.
Leitura complementar: http://www.developer.com/design/article.php/2223551/Object-Diagrams-in-UML.htm
Patrik Guerra
O diagrama de classes faz parte do conjunto de diagramas estruturais UML (Unified Modeling Language). Esse conjunto de diagramas foi concebido para facilitar no planejamento do desenvolvimento de softwares. O diagrama de classe em especifico busca demonstrar como as classes funcionarão em um projeto de desenvolvimento, que utiliza a orientação a objetos.
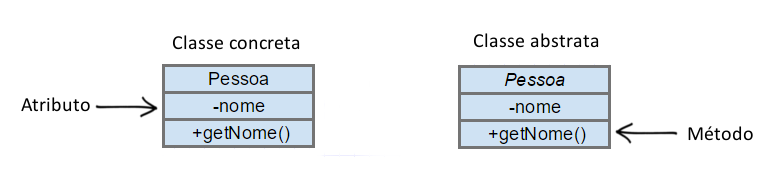
Um diagrama de classe é composto por entidades e seus relacionamentos. Suas entidades podem ser divididas entre classes e interfaces. As classes são representadas no formato de retângulos onde a primeira linha é o nome da classe, a segunda seus atributos e a última os seus métodos. As classes também podem ser representadas concretamente ou de forma abstrata, bastando que para isso seu nome seja escrito em itálico (para classes abstratas). Para representar seus atributos e métodos como privados ou públicos pode ser adotado o sinal de “-” para privado e “+” para público.
Os diagramas de classe contam também com vários componentes, que permitem com que os softwares sejam representando de maneira muito clara na forma de diagramas, os mais utilizados são:
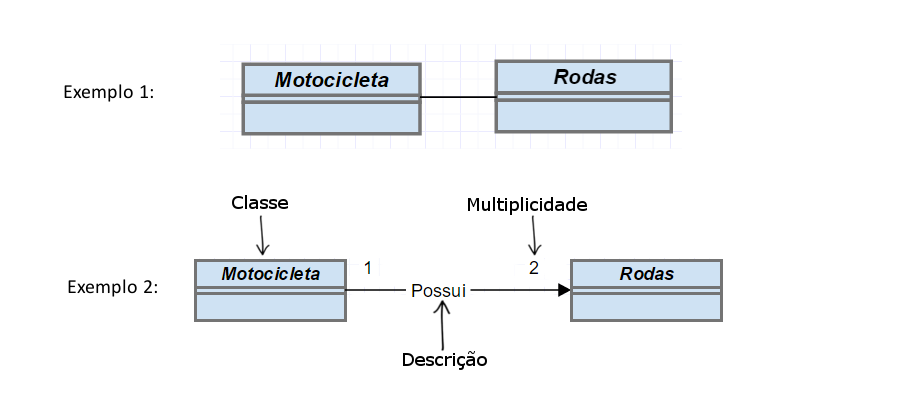
Navegabilidade e multiplicidade: As ligações entre as classes podem ser feitas tanto de forma simples, quanto de maneira mais restrita. Uma ligação simples é representada apenas por uma linha ligando as classes, ou seja, a navegabilidade entre as classes é nos dois sentidos. Como mostrado no “exemplo 1”, onde uma motocicleta pode ter rodas e as rodas podem ter uma motocicleta. Essa representação pode ser um pouco mais restrita, representando melhor a realidade como no (exemplo 2). Onde a navegabilidade é representada por uma seta, demonstrando que uma motocicleta possui as rodas e não o contrário, além da especificação da quantidade dessas rodas sendo demonstrada atravesses de números ao lado das classes (multiplicidade), significando que uma motocicleta pode ter 2 rodas e as rodas são contidas em uma motocicleta.
Herança: representada pelo símbolo de uma seta fechada e com linha continua. O lado em que a seta aponta é a classe que está sendo herdada.
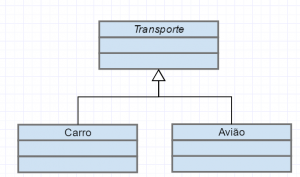
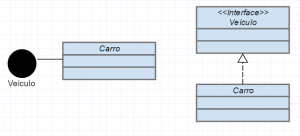
Implementação: Interfaces podem ser representadas por círculos ou também por retângulos com a identificação de interfaces. No caso da primeira opção basta ligar a classe a interface com uma linha continua que simboliza a implementação, já na segunda é utilizada uma seta fechada com linha tracejada.
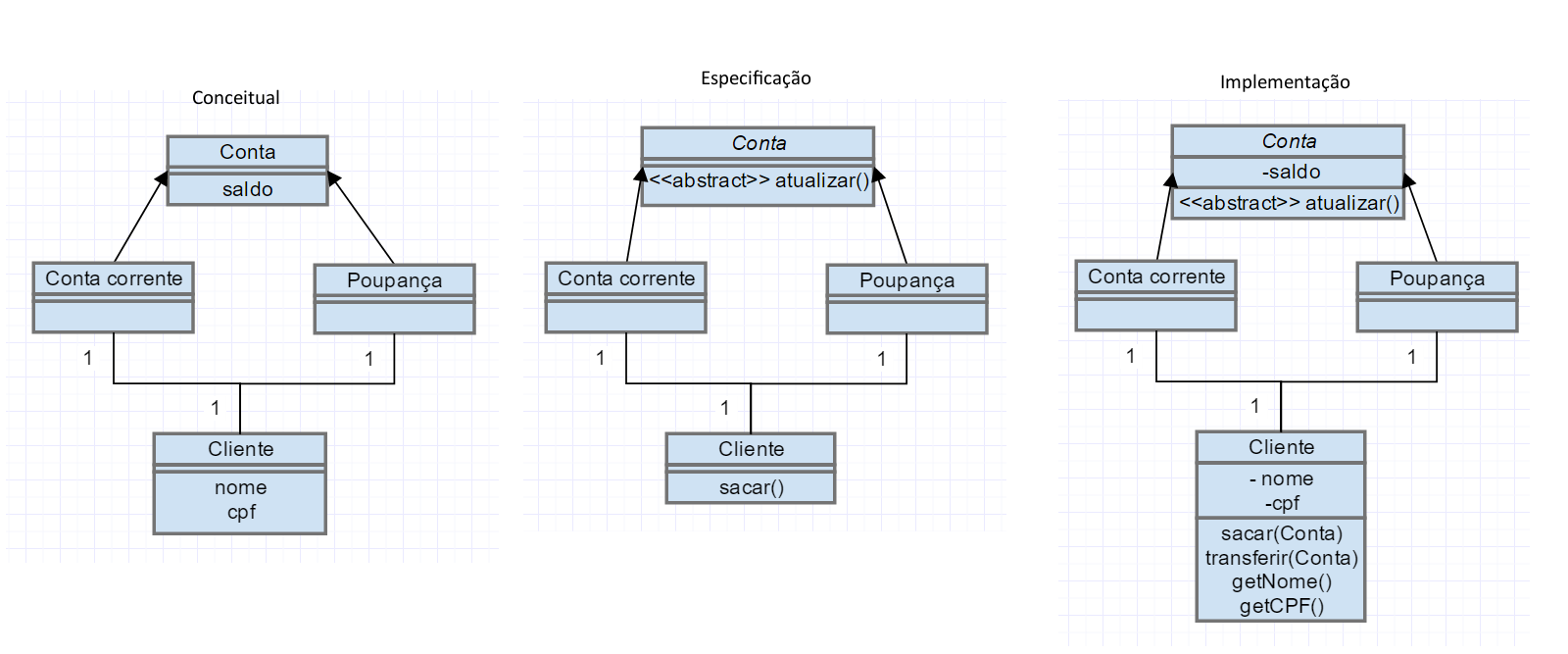
Os diagramas de classe são totalmente voltados a orientação a objetos, possuem três tipos de perspectivas de representação, são elas:
-Conceitual: os diagramas são representados em um domínio mais abstrato, sua forma de demonstrar os acontecimentos é mais voltada para o cliente.
-Especificação: nessa perspectiva os diagramas são voltados a um modo de representação da arquitetura do sistema, demonstrando seus principais métodos, mas não como será feita sua implementação. Voltada para pessoas que não necessariamente precisam saber como o projeto vai ser desenvolvido, mas sim somente como será feita sua estrutura. (Gerentes de projeto).
-Implementação: maneira onde o diagrama demonstra os detalhes de como será a implementação, demonstrando a estrutura das classes e seus atributos. Perspectiva mais voltada aos desenvolvedores, que precisam saber os detalhes das classes.
Graças a essas características os diagramas de classe são excelentes ferramentas para modelagem de sistemas, sejam eles complexos ou simples. Com o uso dos diagramas de classe os sistemas podem ser fielmente representados, de uma maneira que seja fácil de entender e ao mesmo tempo seja útil, facilitando o desenvolvimento do software.
Patrick Pronobi Rodrigues